
将图数据库与 Groovy™ 结合使用

发布时间:2024-09-02 晚上 10:18 (最后更新:2025-03-08 晚上 09:00)
|
让我们使用 Apache TinkerPop、Neo4j、Apache AGE、OrientDB、ArcadeDB、Apache HugeGraph、TuGraph 和 GraphQL 探索图数据库! |
在这篇博文中,我们将探讨如何将属性图数据库与 Groovy 结合使用。我们将探讨
-
属性图数据库技术的一些优势
-
Groovy 的一些特性,让使用这类数据库变得更愉快
-
7 个有趣的图数据库的常见案例研究代码示例
-
使用 GraphQL 的相同案例研究代码示例
案例研究
奥运会又结束了四年。对于体育迷来说,有许多激动人心的时刻。让我们看看过去三年中多次打破奥运纪录的一项赛事。我们将关注女子 100 米仰泳,并使用图数据库对结果进行建模。
为什么选择女子 100 米仰泳?嗯,就打破纪录而言,那是一个特别激动人心的项目。在 2021 年东京奥运会第 4 组中,凯莉·马斯打破了此前由艾米丽·西博姆在 2012 年伦敦奥运会创造的纪录。几分钟后,在第 5 组中,里根·史密斯再次打破了纪录。 फिर 几分钟后,在第 6 组中,凯莉·麦基翁再次打破了纪录。第二天,在半决赛 1 中,里根夺回了纪录。然后,在第二天的决赛中,凯莉再次夺回了纪录。在 2024 年巴黎奥运会中,凯莉在决赛中打破了自己的纪录。几天后,里根在 4x100 米混合泳接力中领衔,在第一棒打破了仰泳纪录。这意味着在过去两届比赛中,纪录被打破了 7 次!

我们的图数据库中将有与游泳运动员和游泳相关的顶点。我们将为这些顶点使用标签 Swimmer 和 Swim。顶点之间将存在诸如 swam 和 supersedes 等关系。我们将探讨使用多种图数据库技术对事件信息进行建模和查询。
本文中的示例可以在 GitHub 上找到。
为什么选择图数据库?
RDBMS 系统比图数据库流行得多,但在许多场景中,图数据库经常被使用。哪些场景呢?通常,它归结为关系。如果您的系统中数据之间存在重要关系,那么图数据库可能是有意义的。典型的使用场景包括欺诈检测、知识图谱、推荐引擎、社交网络和供应链管理。
这篇博文的目的不是让每个人都始终使用图数据库,但我们将向您展示一些可能有用并让您自己决定何时使用的示例。图数据库无疑是您工具箱中非常有用的工具,以备不时之需。
图数据库以在某些场景下查询更简洁、效率更高而闻名。作为第一个例子,您是喜欢这个 Cypher 查询(它来自我们稍后会看到的 TuGraph 代码,但其他技术也类似)
MATCH (sr:Swimmer)-[:swam]->(sm:Swim {at: 'Paris 2024'})
RETURN DISTINCT sr.country AS country还是等效的 SQL 查询,假设我们将信息存储在关系表中
SELECT DISTINCT country FROM Swimmer
LEFT JOIN Swimmer_Swim
ON Swimmer.swimmerId = Swimmer_Swim.fkSwimmer
LEFT JOIN Swim
ON Swim.swimId = Swimmer_Swim.fkSwim
WHERE Swim.at = 'Paris 2024'此 SQL 查询是当我们实体之间存在多对多关系时(在本例中是游泳运动员和游泳)所需查询的典型示例。多对多关系是正确建模接力游泳(例如最后一次破纪录的游泳)所必需的(尽管为了简洁起见,我们没有在数据集中包含其他接力游泳运动员)。该查询中的多次连接对于大型数据集来说也可能非常慢。
我们稍后还会看到其他示例,其中一个是涉及关系遍历的查询。这是 Cypher(同样来自 TuGraph)
MATCH (s1:Swim)-[:supersedes*1..10]->(s2:Swim {at: 'London 2012'})
RETURN s1.at as at, s1.event as event以及等效的 SQL
WITH RECURSIVE traversed(swimId) AS (
SELECT fkNew FROM Supersedes
WHERE fkOld IN (
SELECT swimId FROM Swim
WHERE event = 'Heat 4' AND at = 'London 2012'
)
UNION ALL
SELECT Supersedes.fkNew as swimId
FROM traversed as t
JOIN Supersedes
ON t.swimId = Supersedes.fkOld
WHERE t.swimId = swimId
)
SELECT at, event FROM Swim
WHERE swimId IN (SELECT * FROM traversed)这里我们有一个 Supersedes 表和一个递归 SQL 函数 traversed。细节不重要,但这显示了我们正在研究的这种关系遍历通常所需的复杂性。对于不同类型的遍历(例如最短路径),肯定还有更复杂的 SQL 示例。
此示例使用 TuGraph 的 Cypher 变体作为查询语言。并非我们所有的数据库都支持 Cypher,但它们都具有某种查询语言或 API,可以使此类查询更短。
其他几个数据库确实支持 Cypher 的变体。其他则支持不同的类似 SQL 的查询语言。我们还将看到几个基于 JMV 的数据库,它们支持 TinkerPop/Gremlin。它是一种基于 Groovy 的技术,将是我们探索的第一项技术。最近,ISO 发布了一个国际标准 GQL,用于属性图数据库。我们预计在不久的将来会看到支持该标准的数据库。
现在,是时候使用我们不同的数据库技术来探索案例研究了。我们试图选择那些看起来维护良好、具有合理 JVM 支持并具有任何值得炫耀的功能的技术。我们选择了一些是因为它们支持 TinkerPop/Gremlin。
Apache TinkerPop
我们要考察的第一项技术是 Apache TinkerPop™。

TinkerPop 是一个用于图数据库的开源计算框架。它提供了一个通用的抽象层和一种图查询语言,称为 Gremlin。这允许您以一致的方式使用众多图数据库实现。TinkerPop 还提供自己的图引擎实现,称为 TinkerGraph,这将是我们最初使用的。TinkerPop/Gremlin 将是我们稍后会重新访问其他数据库的技术。
我们将研究 2021 年东京奥运会和 2024 年巴黎奥运会女子 100 米仰泳项目的奖牌获得者和破纪录者的游泳成绩。作为参考,我们还将包括此前创造奥运纪录的游泳成绩。
我们将从创建一个新的内存图数据库开始,并创建一个辅助对象来遍历图
var graph = TinkerGraph.open()
var g = traversal().withEmbedded(graph)接下来,让我们创建与在 2012 年伦敦奥运会上设定的奥运纪录相关的信息。艾米丽·西博姆在第 4 组中创造了这项纪录
var es = g.addV('Swimmer').property(name: 'Emily Seebohm', country: '🇦🇺').next()
swim1 = g.addV('Swim').property(at: 'London 2012', event: 'Heat 4', time: 58.23, result: 'First').next()
es.addEdge('swam', swim1)我们可以通过分别查询两个新创建节点(顶点)的属性来打印出它们的一些信息
var (name, country) = ['name', 'country'].collect { es.value(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.value(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"其输出如下
Emily Seebohm from 🇦🇺 swam a time of 58.23 in Heat 4 at the London 2012 Olympics
到目前为止,我们只使用了 TinkerPop 的 Java API。它还为 Groovy 提供了一些额外的语法糖。我们可以通过以下方式启用语法糖:
SugarLoader.load()这样我们就可以写出(而不是前面三行)稍微短一点的代码
println "$es.name from $es.country swam a time of $swim1.time in $swim1.event at the $swim1.at Olympics"这使用了 Groovy 的正常属性访问语法,并且在执行时具有相同的输出。
让我们创建一些辅助方法来简化剩余信息的创建。
def insertSwimmer(TraversalSource g, name, country) {
g.addV('Swimmer').property(name: name, country: country).next()
}
def insertSwim(TraversalSource g, at, event, time, result, swimmer) {
var swim = g.addV('Swim').property(at: at, event: event, time: time, result: result).next()
swimmer.addEdge('swam', swim)
swim
}现在我们可以创建剩余的游泳信息了
var km = insertSwimmer(g, 'Kylie Masse', '🇨🇦')
var swim2 = insertSwim(g, 'Tokyo 2021', 'Heat 4', 58.17, 'First', km)
swim2.addEdge('supersedes', swim1)
var swim3 = insertSwim(g, 'Tokyo 2021', 'Final', 57.72, '🥈', km)
var rs = insertSwimmer(g, 'Regan Smith', '🇺🇸')
var swim4 = insertSwim(g, 'Tokyo 2021', 'Heat 5', 57.96, 'First', rs)
swim4.addEdge('supersedes', swim2)
var swim5 = insertSwim(g, 'Tokyo 2021', 'Semifinal 1', 57.86, '', rs)
var swim6 = insertSwim(g, 'Tokyo 2021', 'Final', 58.05, '🥉', rs)
var swim7 = insertSwim(g, 'Paris 2024', 'Final', 57.66, '🥈', rs)
var swim8 = insertSwim(g, 'Paris 2024', 'Relay leg1', 57.28, 'First', rs)
var kmk = insertSwimmer(g, 'Kaylee McKeown', '🇦🇺')
var swim9 = insertSwim(g, 'Tokyo 2021', 'Heat 6', 57.88, 'First', kmk)
swim9.addEdge('supersedes', swim4)
swim5.addEdge('supersedes', swim9)
var swim10 = insertSwim(g, 'Tokyo 2021', 'Final', 57.47, '🥇', kmk)
swim10.addEdge('supersedes', swim5)
var swim11 = insertSwim(g, 'Paris 2024', 'Final', 57.33, '🥇', kmk)
swim11.addEdge('supersedes', swim10)
swim8.addEdge('supersedes', swim11)
var kb = insertSwimmer(g, 'Katharine Berkoff', '🇺🇸')
var swim12 = insertSwim(g, 'Paris 2024', 'Final', 57.98, '🥉', kb)请注意,我们只输入了获得奖牌或打破奥运纪录的游泳。如果愿意,我们可以轻松添加更多游泳运动员、其他泳姿和距离、接力项目,甚至其他运动。
让我们看看我们的图现在是什么样子
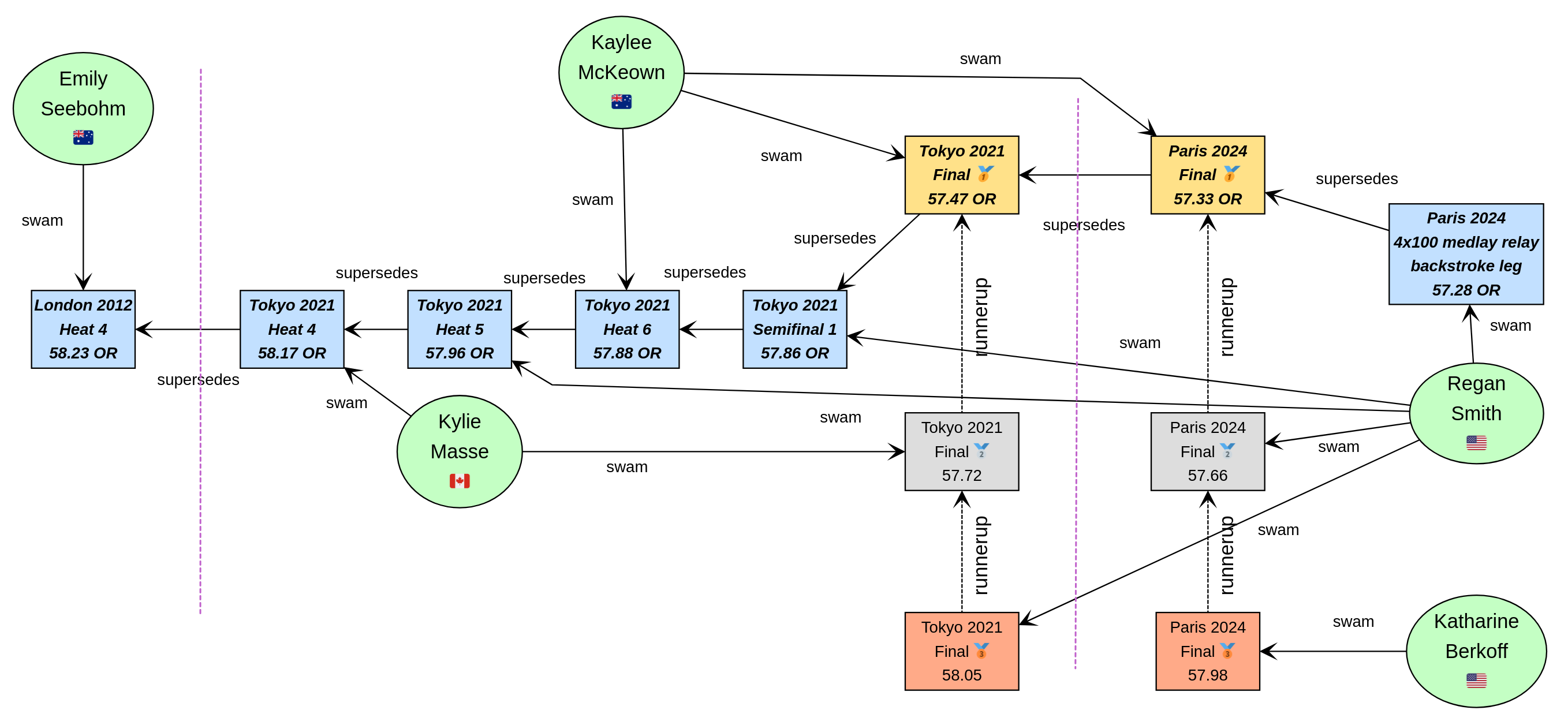
我们现在可能希望以多种方式查询图。例如,哪些国家在 2024 年巴黎奥运会上取得了成功,这里的成功定义为赢得奖牌或打破纪录。当然,仅仅有游泳运动员进入奥运队就是巨大的成功——但为了简单起见,我们暂时保持示例的简单性。
var successInParis = g.V().out('swam').has('at', 'Paris 2024').in()
.values('country').toSet()
assert successInParis == ['🇺🇸', '🇦🇺'] as Set解释一下,我们找到所有具有指向 2024 年巴黎奥运会游泳比赛的传出 swam 边的节点,即所有来自 2024 年巴黎奥运会的游泳运动员。然后我们找到代表的国家集。我们在这里使用集合来去除重复项,而且我们不强制返回结果的顺序,因此我们比较两边的集合。
同样,我们可以找到在预赛中创造的奥运纪录
var recordSetInHeat = g.V().has('Swim','event', startingWith('Heat')).values('at').toSet()
assert recordSetInHeat == ['London 2012', 'Tokyo 2021'] as Set或者,我们可以找到决赛中创造的记录时间
var recordTimesInFinals = g.V().has('event', 'Final').as('ev').out('supersedes')
.select('ev').values('time').toSet()
assert recordTimesInFinals == [57.47, 57.33] as Set利用 Groovy 的语法糖可以得到更简单的版本
var successInParis = g.V.out('swam').has('at', 'Paris 2024').in.country.toSet
assert successInParis == ['🇺🇸', '🇦🇺'] as Set
var recordSetInHeat = g.V.has('Swim','event', startingWith('Heat')).at.toSet
assert recordSetInHeat == ['London 2012', 'Tokyo 2021'] as Set
var recordTimesInFinals = g.V.has('event', 'Final').as('ev').out('supersedes').select('ev').time.toSet
assert recordTimesInFinals == [57.47, 57.33] as SetGroovy 擅长允许您为自己的程序或现有类添加语法糖。TinkerPop 的特殊 Groovy 支持只是其中的一个例子。您的供应商当然可以为您的首选图数据库提供这样的功能(为什么不问问他们呢?),但我们很快就会在探索 Neo4j 时,看看您如何自己编写这样的语法糖。
我们目前为止的例子都很有趣,但图数据库在执行涉及多次边缘遍历的查询时表现出色。让我们看看 2021 年和 2024 年设定的所有奥运纪录,即伦敦 2012 年(之前的 swim1)之后设定的所有纪录
println "Olympic records after ${g.V(swim1).values('at', 'event').toList().join(' ')}: "
println g.V(swim1).repeat(in('supersedes')).as('sw').emit()
.values('at').concat(' ')
.concat(select('sw').values('event')).toList().join('\n')或者在使用 Groovy 语法糖后,查询变为
println g.V(swim1).repeat(in('supersedes')).as('sw').emit
.at.concat(' ').concat(select('sw').event).toList.join('\n')两者都有此输出
Olympic records after London 2012 Heat 4: Tokyo 2021 Heat 4 Tokyo 2021 Heat 5 Tokyo 2021 Heat 6 Tokyo 2021 Semifinal 1 Tokyo 2021 Final Paris 2024 Final Paris 2024 Relay leg1
|
注意
|
虽然对我们的示例不重要,但 TinkerPop 有一个 GraphMLWriter 类,可以以 GraphML 格式输出我们的图,这就是前面图和节点图像最初的生成方式。 |
Neo4j
我们要考察的下一项技术是 neo4j。Neo4j 是一个存储节点和边的图数据库。节点和边可以有标签和属性(或特性)。

Neo4j 使用枚举来建模边缘关系。让我们为我们的示例创建一个枚举
enum SwimmingRelationships implements RelationshipType {
swam, supersedes, runnerup
}我们将以嵌入模式使用 Neo4j,并将其所有操作作为事务的一部分执行
// ... set up managementService ...
var graphDb = managementService.database(DEFAULT_DATABASE_NAME)
try (Transaction tx = graphDb.beginTx()) {
// ... other Neo4j code below here ...
}让我们使用 Neo4j 创建我们的节点和边。首先是现有的奥运纪录
es = tx.createNode(label('Swimmer'))
es.setProperty('name', 'Emily Seebohm')
es.setProperty('country', '🇦🇺')
swim1 = tx.createNode(label('Swim'))
swim1.setProperty('event', 'Heat 4')
swim1.setProperty('at', 'London 2012')
swim1.setProperty('result', 'First')
swim1.setProperty('time', 58.23d)
es.createRelationshipTo(swim1, swam)
var name = es.getProperty('name')
var country = es.getProperty('country')
var at = swim1.getProperty('at')
var event = swim1.getProperty('event')
var time = swim1.getProperty('time')
println "$name from $country swam a time of $time in $event at the $at Olympics"虽然这段代码没有问题,但 Groovy 有许多特性可以使代码更简洁。让我们使用一些动态元编程来实现这一点。
Node.metaClass {
propertyMissing { String name, val -> delegate.setProperty(name, val) }
propertyMissing { String name -> delegate.getProperty(name) }
methodMissing { String name, args ->
delegate.createRelationshipTo(args[0], SwimmingRelationships."$name")
}
}这是做什么的?propertyMissing 行捕获了使用 Groovy 正常属性访问的尝试,并将其通过适当的 getProperty 和 setProperty 方法进行引导。methodMissing 行意味着任何我们无法识别的尝试方法调用都旨在创建关系,因此我们将其通过适当的 createRelationshipTo 方法调用进行引导。
现在我们可以使用 Groovy 的正常属性访问来设置节点属性。它看起来更整洁。我们只需调用一个具有关系名称的方法即可定义边缘关系。
km = tx.createNode(label('Swimmer'))
km.name = 'Kylie Masse'
km.country = '🇨🇦'代码已经更简洁了,但我们可以对元编程稍作修改,以消除与 label 方法相关的噪音
Transaction.metaClass {
createNode { String labelName -> delegate.createNode(label(labelName)) }
}这为 createNode 添加了一个接受 String 的重载,并且节点创建再次得到改进,如我们在此处所见
swim2 = tx.createNode('Swim')
swim2.time = 58.17d
swim2.result = 'First'
swim2.event = 'Heat 4'
swim2.at = 'Tokyo 2021'
km.swam(swim2)
swim2.supersedes(swim1)
swim3 = tx.createNode('Swim')
swim3.time = 57.72d
swim3.result = '🥈'
swim3.event = 'Final'
swim3.at = 'Tokyo 2021'
km.swam(swim3)关系的的代码当然也整洁了很多,而且定义必要的元编程工作量很小。
再多做一点工作,我们可以使用静态元编程技术。这将使我们获得更好的 IDE 补全。我们将在本文末尾讨论改进的类型检查。不过,现在让我们继续定义图的其余部分。
我们可以使用 Neo4j 实现调用重新定义我们的 insertSwimmer 和 insertSwim 方法,然后我们可以使用我们之前的代码来创建我们的图。现在让我们看看查询是什么样的。我们将从通过 API 查询开始,稍后查看使用 Cypher。
首先,2024 年巴黎奥运会的成功国家
var swimmers = [es, km, rs, kmk, kb]
var successInParis = swimmers.findAll { swimmer ->
swimmer.getRelationships(swam).any { run ->
run.getOtherNode(swimmer).at == 'Paris 2024'
}
}
assert successInParis*.country.unique() == ['🇺🇸', '🇦🇺']然后,哪些奥运会上预赛中打破了纪录
var swims = [swim1, swim2, swim3, swim4, swim5, swim6, swim7, swim8, swim9, swim10, swim11, swim12]
var recordSetInHeat = swims.findAll { swim ->
swim.event.startsWith('Heat')
}*.at
assert recordSetInHeat.unique() == ['London 2012', 'Tokyo 2021']现在,决赛中打破纪录的时间是多少
var recordTimesInFinals = swims.findAll { swim ->
swim.event == 'Final' && swim.hasRelationship(supersedes)
}*.time
assert recordTimesInFinals == [57.47d, 57.33d]为了查看遍历的实际操作,Neo4j 有一个特殊的 API 用于执行此类查询
var info = { s -> "$s.at $s.event" }
println "Olympic records following ${info(swim1)}:"
for (Path p in tx.traversalDescription()
.breadthFirst()
.relationships(supersedes)
.evaluator(Evaluators.fromDepth(1))
.uniqueness(Uniqueness.NONE)
.traverse(swim1)) {
println p.endNode().with(info)
}较早版本的 Neo4j 也支持 Gremlin,因此我们可以像 TinkerPop 那样编写查询。该技术在 Neo4j 最新版本中已被弃用,取而代之的是 Cypher 查询语言。我们可以使用该语言进行我们之前的所有查询,如下所示
assert tx.execute('''
MATCH (s:Swim WHERE s.event STARTS WITH 'Heat')
WITH s.at as at
WITH DISTINCT at
RETURN at
''')*.at == ['London 2012', 'Tokyo 2021']
assert tx.execute('''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time AS time
''')*.time == [57.47d, 57.33d]
tx.execute('''
MATCH (s1:Swim)-[:supersedes]->{1,}(s2:Swim { at: $at })
RETURN s1
''', [at: swim1.at])*.s1.each { s ->
println "$s.at $s.event"
}这篇博文当然不是高级图数据库设计课程,但值得注意几点。
决定哪些信息应存储为节点属性,哪些应存储为关系,仍然需要开发人员的判断。例如,我们可以向我们的 Swim 节点添加一个布尔 olympicRecord 属性。某些查询现在可能会变得更简单,或者至少对传统 RDBMS SQL 开发人员来说更熟悉,但其他查询可能会变得更难编写,并且效率可能低得多。这是需要仔细思考并有时进行实验的事情。
假设在打破纪录的情况下,我们想看看还有哪些游泳运动员(在我们的案例中是决赛中的奖牌获得者)也打破了之前的纪录。我们可以编写一个查询来找到它,如下所示
assert tx.execute('''
MATCH (sr1:Swimmer)-[:swam]->(sm1:Swim {event: 'Final'}), (sm2:Swim {event: 'Final'})-[:supersedes]->(sm3:Swim)
WHERE sm1.at = sm2.at AND sm1 <> sm2 AND sm1.time < sm3.time
RETURN sr1.name as name
''')*.name == ['Kylie Masse']不算太糟糕,但如果我们的数据图更大,可能会非常慢。我们可以选择在我们的图中添加一个额外的关系,称为 runnerup。
swim6.runnerup(swim3)
swim3.runnerup(swim10)
swim12.runnerup(swim7)
swim7.runnerup(swim11)可视化效果如下所示
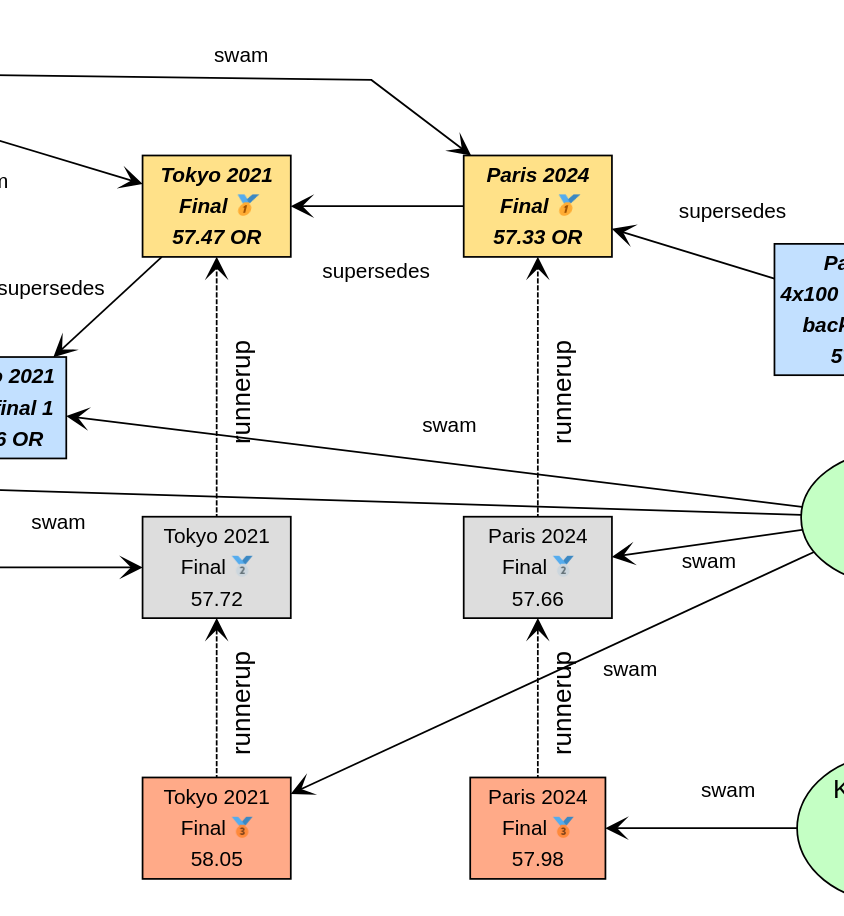
它本质上使得如果我们知道其中任何一个,就更容易找到其他奖牌获得者。
结果查询变为
assert tx.execute('''
MATCH (sr1:Swimmer)-[:swam]->(sm1:Swim {event: 'Final'})-[:runnerup]->{1,2}(sm2:Swim {event: 'Final'})-[:supersedes]->(sm3:Swim)
WHERE sm1.time < sm3.time
RETURN sr1.name as name
''')*.name == ['Kylie Masse']MATCH 子句的复杂性相似,WHERE 子句要简单得多。查询可能也更快,但这是一个需要权衡的取舍。
Apache AGE
我们将要考察的下一项技术是 Apache AGE™ 图数据库。Apache AGE 利用 PostgreSQL 进行存储。
![]()
![]()
我们通过 Docker 镜像安装了 Apache AGE,如 Apache AGE 手册中所述。
由于 Apache AGE 提供类似 SQL 的图数据库体验,我们使用 Groovy 的 SQL 功能与数据库进行交互
Sql.withInstance(DB_URL, USER, PASS, 'org.postgresql.jdbc.PgConnection') { sql ->
// enable Apache AGE extension, then use Sql connection ...
}为了创建我们的节点和后续查询,我们使用带有嵌入式 cypher 子句的 SQL 语句。这是创建节点和边的语句
sql.execute'''
SELECT * FROM cypher('swimming_graph', $$ CREATE
(es:Swimmer {name: 'Emily Seebohm', country: '🇦🇺'}),
(swim1:Swim {event: 'Heat 4', result: 'First', time: 58.23, at: 'London 2012'}),
(es)-[:swam]->(swim1),
(km:Swimmer {name: 'Kylie Masse', country: '🇨🇦'}),
(swim2:Swim {event: 'Heat 4', result: 'First', time: 58.17, at: 'Tokyo 2021'}),
(km)-[:swam]->(swim2),
(swim2)-[:supersedes]->(swim1),
(swim3:Swim {event: 'Final', result: '🥈', time: 57.72, at: 'Tokyo 2021'}),
(km)-[:swam]->(swim3),
(rs:Swimmer {name: 'Regan Smith', country: '🇺🇸'}),
(swim4:Swim {event: 'Heat 5', result: 'First', time: 57.96, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim4),
(swim4)-[:supersedes]->(swim2),
(swim5:Swim {event: 'Semifinal 1', result: 'First', time: 57.86, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim5),
(swim6:Swim {event: 'Final', result: '🥉', time: 58.05, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim6),
(swim7:Swim {event: 'Final', result: '🥈', time: 57.66, at: 'Paris 2024'}),
(rs)-[:swam]->(swim7),
(swim8:Swim {event: 'Relay leg1', result: 'First', time: 57.28, at: 'Paris 2024'}),
(rs)-[:swam]->(swim8),
(kmk:Swimmer {name: 'Kaylee McKeown', country: '🇦🇺'}),
(swim9:Swim {event: 'Heat 6', result: 'First', time: 57.88, at: 'Tokyo 2021'}),
(kmk)-[:swam]->(swim9),
(swim9)-[:supersedes]->(swim4),
(swim5)-[:supersedes]->(swim9),
(swim10:Swim {event: 'Final', result: '🥇', time: 57.47, at: 'Tokyo 2021'}),
(kmk)-[:swam]->(swim10),
(swim10)-[:supersedes]->(swim5),
(swim11:Swim {event: 'Final', result: '🥇', time: 57.33, at: 'Paris 2024'}),
(kmk)-[:swam]->(swim11),
(swim11)-[:supersedes]->(swim10),
(swim8)-[:supersedes]->(swim11),
(kb:Swimmer {name: 'Katharine Berkoff', country: '🇺🇸'}),
(swim12:Swim {event: 'Final', result: '🥉', time: 57.98, at: 'Paris 2024'}),
(kb)-[:swam]->(swim12)
$$) AS (a agtype)
'''要找到哪些奥运会上在预赛中创造了纪录,我们可以使用以下 cypher 查询
assert sql.rows('''
SELECT * from cypher('swimming_graph', $$
MATCH (s:Swim)
WHERE left(s.event, 4) = 'Heat'
RETURN s
$$) AS (a agtype)
''').a*.map*.get('properties')*.at.toUnique() == ['London 2012', 'Tokyo 2021']结果以一种特殊的类似 JSON 的数据类型 agtype 返回。从中,我们可以查询属性并返回 at 属性。我们选择唯一的值以去除重复项。
同样,我们可以如下所示找到决赛中创造的奥运纪录时间
assert sql.rows('''
SELECT * from cypher('swimming_graph', $$
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1
$$) AS (a agtype)
''').a*.map*.get('properties')*.time == [57.47, 57.33]要打印出 2021 年东京奥运会和 2024 年巴黎奥运会期间设定的所有奥运纪录,我们可以使用 eachRow 和以下查询
sql.eachRow('''
SELECT * from cypher('swimming_graph', $$
MATCH (s1:Swim)-[:supersedes]->(swim1)
RETURN s1
$$) AS (a agtype)
''') {
println it.a*.map*.get('properties')[0].with{ "$it.at $it.event" }
}输出如下
Tokyo 2021 Heat 4 Tokyo 2021 Heat 5 Tokyo 2021 Heat 6 Tokyo 2021 Final Tokyo 2021 Semifinal 1 Paris 2024 Final Paris 2024 Relay leg1
Apache AGE 项目还维护一个查看器工具,提供基于 Web 的用户界面,用于可视化存储在我们数据库中的图数据。安装说明可在 GitHub 站点上找到。该工具允许可视化任何查询的结果。对于我们的数据库,查询所有节点和边会生成如下图所示的可视化效果(我们选择手动重新排列节点)
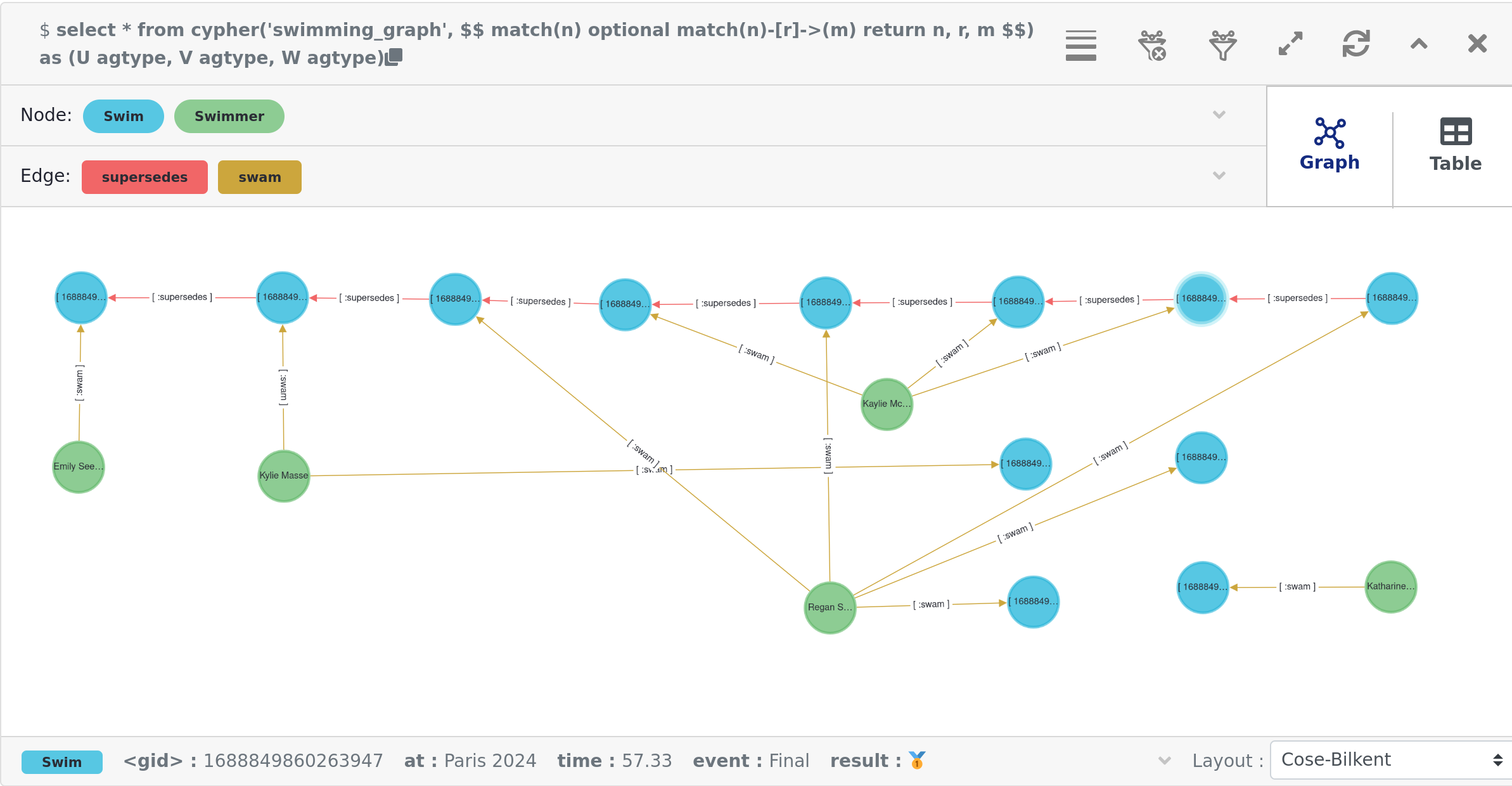
OrientDB
![]()
OrientDB(以及我们接下来将介绍的密切相关的 ArcadeDB)的主要卖点是它们是多模型数据库,支持在同一个数据库中存储图和文档。
创建我们的数据库并设置我们的顶点和边类(可以看作是微型模式)如下所示
try (var db = context.open("swimming", "admin", "adminpwd")) {
db.createVertexClass('Swimmer')
db.createVertexClass('Swim')
db.createEdgeClass('swam')
db.createEdgeClass('supersedes')
// other code here
}有关更多详细信息,请参阅 GitHub 仓库。
初始化完成后,我们可以开始定义我们的节点和边
var es = db.newVertex('Swimmer')
es.setProperty('name', 'Emily Seebohm')
es.setProperty('country', '🇦🇺')
var swim1 = db.newVertex('Swim')
swim1.setProperty('at', 'London 2012')
swim1.setProperty('result', 'First')
swim1.setProperty('event', 'Heat 4')
swim1.setProperty('time', 58.23)
es.addEdge(swim1, 'swam')我们可以像以前一样打印出详细信息
var (name, country) = ['name', 'country'].collect { es.getProperty(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.getProperty(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"此时,我们可以应用一些 Groovy 元编程来使代码更简洁,但我们将像以前一样填充我们的 insertSwimmer 和 insertSwim 辅助方法。我们可以使用这些方法输入剩余的游泳信息。
查询是使用多模型 API 和类似 SQL 的查询执行的。我们之前看到的三个查询如下所示:
var results = db.query("SELECT expand(out('supersedes').in('supersedes')) FROM Swim WHERE event = 'Final'")
assert results*.getProperty('time').toSet() == [57.47, 57.33] as Set
results = db.query("SELECT expand(out('supersedes')) FROM Swim WHERE event.left(4) = 'Heat'")
assert results*.getProperty('at').toSet() == ['Tokyo 2021', 'London 2012'] as Set
results = db.query("SELECT country FROM ( SELECT expand(in('swam')) FROM Swim WHERE at = 'Paris 2024' )")
assert results*.getProperty('country').toSet() == ['🇺🇸', '🇦🇺'] as Set遍历看起来像这样
results = db.query("TRAVERSE in('supersedes') FROM :swim", swim1)
results.each {
if (it.toElement() != swim1) {
println "${it.getProperty('at')} ${it.getProperty('event')}"
}
}OrientDB 还支持 Gremlin 和 Studio Web-UI。这两个功能与 ArcadeDB 的对应功能非常相似。我们接下来在查看 ArcadeDB 时会对其进行研究。
ArcadeDB
现在,我们将研究 ArcadeDB。
![]()
ArcadeDB 是 OrientDB 的重写/部分分支,并继承了其多模型的特性。我们以嵌入模式使用它,但如果您喜欢,也有运行 docker 镜像的说明。
毫不奇怪,ArcadeDB 的一些用法与 OrientDB 非常相似。初始化略有变化
var factory = new DatabaseFactory("swimming")
try (var db = factory.create()) {
db.transaction { ->
db.schema.with {
createVertexType('Swimmer')
createVertexType('Swim')
createEdgeType('swam')
createEdgeType('supersedes')
}
// ... other code goes here ...
}
}定义现有记录信息如下所示
var es = db.newVertex('Swimmer')
es.set(name: 'Emily Seebohm', country: '🇦🇺').save()
var swim1 = db.newVertex('Swim')
swim1.set(at: 'London 2012', result: 'First', event: 'Heat 4', time: 58.23).save()
swim1.newEdge('swam', es, false).save()访问信息可以像这样完成
var (name, country) = ['name', 'country'].collect { es.get(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.get(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"ArcadeDB 支持多种查询语言。类似 SQL 的语言与 OrientDB 提供的内容类似。这是我们现在熟悉的三个查询
var results = db.query('SQL', '''
SELECT expand(outV()) FROM (SELECT expand(outE('supersedes')) FROM Swim WHERE event = 'Final')
''')
assert results*.toMap().time.toSet() == [57.47, 57.33] as Set
results = db.query('SQL', "SELECT expand(outV()) FROM (SELECT expand(outE('supersedes')) FROM Swim WHERE event.left(4) = 'Heat')")
assert results*.toMap().at.toSet() == ['Tokyo 2021', 'London 2012'] as Set
results = db.query('SQL', "SELECT country FROM ( SELECT expand(out('swam')) FROM Swim WHERE at = 'Paris 2024' )")
assert results*.toMap().country.toSet() == ['🇺🇸', '🇦🇺'] as Set这是我们的遍历示例
results = db.query('SQL', "TRAVERSE out('supersedes') FROM :swim", swim1)
results.each {
if (it.toElement() != swim1) {
var props = it.toMap()
println "$props.at $props.event"
}
}ArcadeDB 也支持 Cypher 查询(如 Neo4j)。使用 Cypher 方言查询决赛中的记录时间如下所示
results = db.query('cypher', '''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time AS time
''')
assert results*.toMap().time.toSet() == [57.47, 57.33] as SetArcadeDB 也支持 Gremlin 查询。使用 Gremlin 方言查询决赛中的记录时间如下所示
results = db.query('gremlin', '''
g.V().has('event', 'Final').as('ev').out('supersedes').select('ev').values('time')
''')
assert results*.toMap().result.toSet() == [57.47, 57.33] as Set我们不仅可以作为字符串传递 Gremlin 查询,还可以完全访问 TinkerPop 环境,如下例所示
try (final ArcadeGraph graph = ArcadeGraph.open("swimming")) {
var recordTimesInFinals = graph.traversal().V().has('event', 'Final').as('ev').out('supersedes')
.select('ev').values('time').toSet()
assert recordTimesInFinals == [57.47, 57.33] as Set
}ArcadeDB 也支持 Studio Web-UI。这是一个使用 Studio 查询与 2021 年东京奥运会相关的所有节点和边的示例

TuGraph
接下来,我们将看看 TuGraph。

有几种方式可以与 TuGraph 交互。我们将使用推荐的 Neo4j Bolt 客户端,它使用 Bolt 协议与 TuGraph 服务器进行通信。
我们将使用该客户端创建一个会话,并提供一个辅助 run 方法来调用我们的查询。
var authToken = AuthTokens.basic("admin", "73@TuGraph")
var driver = GraphDatabase.driver("bolt://:7687", authToken)
var session = driver.session(SessionConfig.forDatabase("default"))
var run = { String s -> session.run(s) }接下来,我们设置数据库,包括为我们的节点、边和属性提供一个模式。与之前的示例不同的一点是,TuGraph 需要为每个顶点提供一个主键。因此,我们为 Swim 顶点添加了 id。
'''
CALL db.dropDB()
CALL db.createVertexLabel('Swimmer', 'name', 'name', 'STRING', false, 'country', 'STRING', false)
CALL db.createVertexLabel('Swim', 'id', 'id', 'INT32', false, 'event', 'STRING', false, 'result', 'STRING', false, 'at', 'STRING', false, 'time', 'FLOAT', false)
CALL db.createEdgeLabel('swam','[["Swimmer","Swim"]]')
CALL db.createEdgeLabel('supersedes','[["Swim","Swim"]]')
'''.trim().readLines().each{ run(it) }定义好这些后,我们可以创建我们的游泳信息
run '''create
(es:Swimmer {name: 'Emily Seebohm', country: '🇦🇺'}),
(swim1:Swim {event: 'Heat 4', result: 'First', time: 58.23, at: 'London 2012', id:1}),
(es)-[:swam]->(swim1),
(km:Swimmer {name: 'Kylie Masse', country: '🇨🇦'}),
(swim2:Swim {event: 'Heat 4', result: 'First', time: 58.17, at: 'Tokyo 2021', id:2}),
(km)-[:swam]->(swim2),
(swim3:Swim {event: 'Final', result: '🥈', time: 57.72, at: 'Tokyo 2021', id:3}),
(km)-[:swam]->(swim3),
(swim2)-[:supersedes]->(swim1),
(rs:Swimmer {name: 'Regan Smith', country: '🇺🇸'}),
(swim4:Swim {event: 'Heat 5', result: 'First', time: 57.96, at: 'Tokyo 2021', id:4}),
(rs)-[:swam]->(swim4),
(swim5:Swim {event: 'Semifinal 1', result: 'First', time: 57.86, at: 'Tokyo 2021', id:5}),
(rs)-[:swam]->(swim5),
(swim6:Swim {event: 'Final', result: '🥉', time: 58.05, at: 'Tokyo 2021', id:6}),
(rs)-[:swam]->(swim6),
(swim7:Swim {event: 'Final', result: '🥈', time: 57.66, at: 'Paris 2024', id:7}),
(rs)-[:swam]->(swim7),
(swim8:Swim {event: 'Relay leg1', result: 'First', time: 57.28, at: 'Paris 2024', id:8}),
(rs)-[:swam]->(swim8),
(swim4)-[:supersedes]->(swim2),
(kmk:Swimmer {name: 'Kaylee McKeown', country: '🇦🇺'}),
(swim9:Swim {event: 'Heat 6', result: 'First', time: 57.88, at: 'Tokyo 2021', id:9}),
(kmk)-[:swam]->(swim9),
(swim9)-[:supersedes]->(swim4),
(swim5)-[:supersedes]->(swim9),
(swim10:Swim {event: 'Final', result: '🥇', time: 57.47, at: 'Tokyo 2021', id:10}),
(kmk)-[:swam]->(swim10),
(swim10)-[:supersedes]->(swim5),
(swim11:Swim {event: 'Final', result: '🥇', time: 57.33, at: 'Paris 2024', id:11}),
(kmk)-[:swam]->(swim11),
(swim11)-[:supersedes]->(swim10),
(swim8)-[:supersedes]->(swim11),
(kb:Swimmer {name: 'Katharine Berkoff', country: '🇺🇸'}),
(swim12:Swim {event: 'Final', result: '🥉', time: 57.98, at: 'Paris 2024', id:12}),
(kb)-[:swam]->(swim12)
'''TuGraph 使用 Cypher 风格的查询。这是我们三个标准查询
assert run('''
MATCH (sr:Swimmer)-[:swam]->(sm:Swim {at: 'Paris 2024'})
RETURN DISTINCT sr.country AS country
''')*.get('country')*.asString().toSet() == ['🇺🇸', '🇦🇺'] as Set
assert run('''
MATCH (s:Swim)
WHERE s.event STARTS WITH 'Heat'
RETURN DISTINCT s.at AS at
''')*.get('at')*.asString().toSet() == ["London 2012", "Tokyo 2021"] as Set
assert run('''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time as time
''')*.get('time')*.asDouble().toSet() == [57.47d, 57.33d] as Set这是我们的遍历查询
run('''
MATCH (s1:Swim)-[:supersedes*1..10]->(s2:Swim {at: 'London 2012'})
RETURN s1.at as at, s1.event as event
''')*.asMap().each{ println "$it.at $it.event" }Apache HugeGraph
我们最后一项技术是 Apache HugeGraph。它是一个在 ASF 孵化中的项目。

HugeGraph 的主要卖点是支持超大型图数据库的能力。同样,这个例子并不真正需要,但玩起来应该很有趣。我们使用了文档中描述的 docker 镜像。
设置涉及为与服务器(在 docker 镜像上运行)通信创建客户端
var client = HugeClient.builder("https://:8080", "hugegraph").build()接下来,我们为我们的图数据库定义了模式
var schema = client.schema()
schema.propertyKey("num").asInt().ifNotExist().create()
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("country").asText().ifNotExist().create()
schema.propertyKey("at").asText().ifNotExist().create()
schema.propertyKey("event").asText().ifNotExist().create()
schema.propertyKey("result").asText().ifNotExist().create()
schema.propertyKey("time").asDouble().ifNotExist().create()
schema.vertexLabel('Swimmer')
.properties('name', 'country')
.primaryKeys('name')
.ifNotExist()
.create()
schema.vertexLabel('Swim')
.properties('num', 'at', 'event', 'result', 'time')
.primaryKeys('num')
.ifNotExist()
.create()
schema.edgeLabel("swam")
.sourceLabel("Swimmer")
.targetLabel("Swim")
.ifNotExist()
.create()
schema.edgeLabel("supersedes")
.sourceLabel("Swim")
.targetLabel("Swim")
.ifNotExist()
.create()
schema.indexLabel("SwimByEvent")
.onV("Swim")
.by("event")
.secondary()
.ifNotExist()
.create()
schema.indexLabel("SwimByAt")
.onV("Swim")
.by("at")
.secondary()
.ifNotExist()
.create()虽然技术上,HugeGraph 支持复合键,但当 Swim 顶点具有单个主键时,它似乎工作得更好。我们使用了 num 字段,只是给每次游泳一个编号。
我们使用用于创建节点和边的图 API
var g = client.graph()
var es = g.addVertex(T.LABEL, 'Swimmer', 'name', 'Emily Seebohm', 'country', '🇦🇺')
var swim1 = g.addVertex(T.LABEL, 'Swim', 'at', 'London 2012', 'event', 'Heat 4', 'time', 58.23, 'result', 'First', 'num', NUM++)
es.addEdge('swam', swim1)以下是如何打印一些节点信息
var (name, country) = ['name', 'country'].collect { es.property(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.property(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"我们现在创建其他游泳者和游泳的节点和边。
Gremlin 查询通过 Gremlin 辅助对象调用。我们三个标准查询如下所示
var gremlin = client.gremlin()
var successInParis = gremlin.gremlin('''
g.V().out('swam').has('Swim', 'at', 'Paris 2024').in().values('country').dedup().order()
''').execute()
assert successInParis.data() == ['🇦🇺', '🇺🇸']
var recordSetInHeat = gremlin.gremlin('''
g.V().hasLabel('Swim')
.filter { it.get().property('event').value().startsWith('Heat') }
.values('at').dedup().order()
''').execute()
assert recordSetInHeat.data() == ['London 2012', 'Tokyo 2021']
var recordTimesInFinals = gremlin.gremlin('''
g.V().has('Swim', 'event', 'Final').as('ev').out('supersedes').select('ev').values('time').order()
''').execute()
assert recordTimesInFinals.data() == [57.33, 57.47]这是我们的遍历示例
println "Olympic records after ${swim1.properties().subMap(['at', 'event']).values().join(' ')}: "
gremlin.gremlin('''
g.V().has('at', 'London 2012').repeat(__.in('supersedes')).emit().values('at', 'event')
''').execute().data().collate(2).each { a, e ->
println "$a $e"
}GraphQL
到目前为止我们研究的数据库,大多数都支持 Gremlin 或 Cypher 作为其查询语言。近年来,另一个开源图查询语言框架 GraphQL 获得了一些流行。它允许您定义基于图的数据类型和查询,并提供一种查询语言。它通常用于在客户端-服务器场景中定义 API,作为基于 REST 的 API 的替代方案。
虽然在客户端-服务器场景中经常使用,但我们将在本案例研究中探讨使用这项技术。
graphql-java
graphql-java 库提供了 GraphQL 规范的实现。它允许您读取或定义模式和查询定义,并执行查询。我们将这些查询映射到内存数据结构。让我们首先定义这些数据。
我们将使用记录来存储我们的信息
record Swimmer(String name, String country) {}
record Swim(Swimmer who, String at, String result, String event, double time) {}现在让我们创建我们的数据结构
var es = new Swimmer('Emily Seebohm', '🇦🇺')
var km = new Swimmer('Kylie Masse', '🇨🇦')
var rs = new Swimmer('Regan Smith', '🇺🇸')
var kmk = new Swimmer('Kaylee McKeown', '🇦🇺')
var kb = new Swimmer('Katharine Berkoff', '🇺🇸')
var swim1 = new Swim(es, 'London 2012', 'First', 'Heat 4', 58.23)
var swim2 = new Swim(km, 'Tokyo 2021', 'First', 'Heat 4', 58.17)
var swim3 = new Swim(km, 'Tokyo 2021', '🥈', 'Final', 57.72)
var swim4 = new Swim(rs, 'Tokyo 2021', 'First', 'Heat 5', 57.96)
var swim5 = new Swim(rs, 'Tokyo 2021', 'First', 'Semifinal 1', 57.86)
var swim6 = new Swim(rs, 'Tokyo 2021', '🥉', 'Final', 58.05)
var swim7 = new Swim(rs, 'Paris 2024', '🥈', 'Final', 57.66)
var swim8 = new Swim(rs, 'Paris 2024', 'First', 'Relay leg1', 57.28)
var swim9 = new Swim(kmk, 'Tokyo 2021', 'First', 'Heat 6', 57.88)
var swim10 = new Swim(kmk, 'Tokyo 2021', '🥇', 'Final', 57.47)
var swim11 = new Swim(kmk, 'Paris 2024', '🥇', 'Final', 57.33)
var swim12 = new Swim(kb, 'Paris 2024', '🥉', 'Final', 57.98)
var swims = [swim1, swim2, swim3, swim4, swim5, swim6,
swim7, swim8, swim9, swim10, swim11, swim12]这些代表我们的节点,但 Swim 中的 who 字段与先前示例中的 swam 边相同。让我们将 supersedes 边表示为列表
var supersedes = [
[swim2, swim1],
[swim4, swim2],
[swim9, swim4],
[swim5, swim9],
[swim10, swim5],
[swim11, swim10],
[swim8, swim11],
]现在,我们将使用 GraphQL 模式语法定义模式。它将包含游泳和游泳运动员的详细信息,以及一些查询
type Swimmer {
name: String!
country: String!
}
type Swim {
who: Swimmer!
at: String!
result: String!
event: String!
time: Float
}
type Query {
findSwim(name: String!, event: String!, at: String!): Swim!
recordsInFinals: [Swim!]
recordsInHeats: [Swim!]
allRecords: [Swim!]
success(at: String!): [Swim!]
}我们现在将定义我们的 GraphQL 运行时。它将包括模式定义类型和查询 API,但我们还将定义提供程序,这些提供程序定义了如何为每个查询返回我们数据结构中的数据
var generator = new SchemaGenerator()
var types = getClass().getResourceAsStream("/schema.graphqls")
.withReader { reader -> new SchemaParser().parse(reader) }
var swimFetcher = { DataFetchingEnvironment env ->
var name = env.arguments.name
var at = env.arguments.at
var event = env.arguments.event
swims.find{ s -> s.who.name == name && s.at == at && s.event == event }
} as DataFetcher<Swim>
var finalsFetcher = { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event == 'Final' && supersedes.any{ it[0] == s } }
} as DataFetcher<List<Swim>>
var heatsFetcher = { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event.startsWith('Heat') &&
(supersedes[0][1] == s || supersedes.any{ it[0] == s }) }
} as DataFetcher<List<Swim>>
var successFetcher = { DataFetchingEnvironment env ->
var at = env.arguments.at
swims.findAll{ s -> s.at == at }
} as DataFetcher<List<Swim>>
var recordsFetcher = { DataFetchingEnvironment env ->
supersedes.collect{it[0] }
} as DataFetcher<List<Swim>>
var wiring = RuntimeWiring.newRuntimeWiring()
.type("Query") { builder ->
builder.dataFetcher("findSwim", swimFetcher)
builder.dataFetcher("recordsInFinals", finalsFetcher)
builder.dataFetcher("recordsInHeats", heatsFetcher)
builder.dataFetcher("success", successFetcher)
builder.dataFetcher("allRecords", recordsFetcher)
}.build()
var schema = generator.makeExecutableSchema(types, wiring)
var graphQL = GraphQL.newGraphQL(schema).build()我们还将定义一个 execute 辅助方法,该方法使用运行时执行查询
var execute = { String query, Map variables = [:] ->
var executionInput = ExecutionInput.newExecutionInput()
.query(query)
.variables(variables)
.build()
graphQL.execute(executionInput)
}现在让我们来看看如何编写之前的查询。
首先,由于我们有内存数据结构,我们将承认直接使用这些数据结构编写查询很容易,例如
swim1.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}但是,在典型的客户端-服务器环境中,我们无法直接访问我们的数据结构。我们需要使用 GraphQL API。让我们执行相同的查询
execute('''
query findSwim($name: String!, $at: String!, $event: String!) {
findSwim(name: $name, at: $at, event: $event) {
who {
name
country
}
event
at
time
}
}
''', [name: 'Emily Seebohm', at: 'London 2012', event: 'Heat 4']).data.findSwim.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}要查找决赛中创造的奥运纪录时间,我们有一个预定义的查询。我们可以简单地调用该查询并要求返回时间字段
assert execute('''{
recordsInFinals {
time
}
}''').data.recordsInFinals*.time == [57.47, 57.33]稍后我们将看到如何在没有预定义查询的情况下更通用地执行此操作。
同样,我们有一个预定义的查询,用于“在哪个奥运会上,预赛中创造了纪录”
assert execute('''{
recordsInHeats {
at
}
}''').data.recordsInHeats*.at.toUnique() == ['London 2012', 'Tokyo 2021']对于“2024 年巴黎奥运会的成功国家”,我们有一个接受参数的查询
assert execute('''
query success($at: String!) {
success(at: $at) {
who {
country
}
}
}
''', [at: 'Paris 2024']).data.success*.who*.country.toUnique() == ['🇺🇸', '🇦🇺']要“打印 2012 年伦敦奥运会以来的所有记录”,我们使用 allRecords 查询
execute('''{
allRecords {
at
event
}
}''').data.allRecords.each {
println "$it.at $it.event"
}作为 recordsInFinals 和 recordsInHeats 查询的替代方案,我们可以定义一个稍微更通用的查询
var swimsFetcher = { DataFetchingEnvironment env ->
var event = env.arguments.event
var candidates = [supersedes[0][1]] + supersedes.collect(List::first)
candidates.findAll{ s -> event.startsWith('~')
? s.event.matches(event[1..-1])
: s.event == event }
} as DataFetcher<List<Swim>>然后我们的查询将变为
assert execute('''{
findSwims(event: "Final") {
time
}
}''').data?.findSwims*.time == [57.47, 57.33]
assert execute('''{
findSwims(event: "~Heat.*") {
at
}
}''').data?.findSwims*.at.toUnique() == ['London 2012', 'Tokyo 2021']swimsFetcher 数据提供程序可能需要进一步解释。在这里,我们明确定义了一个可以处理文本或正则表达式(以“~”字符开头)查询的提供程序。这是因为 graphql-java 不提供任何开箱即用的过滤。还有其他库,例如 graphql-filter-java 和 graphql-java-filter 提供了这种过滤,但我们在此不作进一步讨论。
GQL
Groovy 生态系统中有各种与 GraphQL 相关的库。让我们看看 GQL,它可以被认为是 graphql-java 之上的 Groovy 语法糖。它使得构建 GraphQL 模式和执行 GraphQL 查询更容易,同时又不失类型安全。
我们首先定义我们的模式。我们可以选择在代码中定义模式,而不是使用 GraphQL 模式格式。graphql-java 库也支持这一点,但使用 GQL 会更好
var swimmerType = DSL.type('Swimmer') {
field 'name', GraphQLString
field 'country', GraphQLString
}
var swimType = DSL.type('Swim') {
field 'who', swimmerType
field 'at', GraphQLString
field 'result', GraphQLString
field 'event', GraphQLString
field 'time', GraphQLFloat
}同样,我们可以声明我们的查询并关联提供程序
var schema = DSL.schema {
queries {
field('findSwim') {
type swimType
argument 'name', GraphQLString
argument 'at', GraphQLString
argument 'event', GraphQLString
fetcher { DataFetchingEnvironment env ->
var name = env.arguments.name
var at = env.arguments.at
var event = env.arguments.event
swims.find{ s -> s.who.name == name && s.at == at && s.event == event }
}
}
field('recordsInFinals') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event == 'Final' && supersedes.any{ it[0] == s } }
}
}
field('recordsInHeats') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event.startsWith('Heat') &&
(supersedes[0][1] == s || supersedes.any{ it[0] == s }) }
}
}
field('success') {
type list(swimmerType)
argument 'at', GraphQLString
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.at == env.arguments.at }*.who
}
}
field('allRecords') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
supersedes.collect{it[0] }
}
}
}
}如前所述,要打印出关于一次游泳的信息,我们可以使用内存数据结构
swim1.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}要使用 GQL,它可能看起来像这样
DSL.execute(schema, '''
query findSwim($name: String!, $at: String!, $event: String!) {
findSwim(name: $name, at: $at, event: $event) {
who {
name
country
}
event
at
time
}
}
''', [name: 'Emily Seebohm', at: 'London 2012', event: 'Heat 4']).data.findSwim.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}这与我们使用 graphql-java 看到的情况类似,但运行时大部分都被隐藏了。
我们的简单查询也与之前类似
assert DSL.execute(schema, '''{
recordsInFinals {
time
}
}''').data.recordsInFinals*.time == [57.47, 57.33]或者,我们可以将查询构建为一个明确的步骤
assert DSL.newExecutor(schema).execute {
query('recordsInHeats') {
returns(Swim) {
at
}
}
}.data.recordsInHeats*.at.toUnique() == ['London 2012', 'Tokyo 2021']或者,我们可以将查询构建为一个显式步骤
var query = DSL.buildQuery {
query('success', [at: 'Paris 2024']) {
returns(Swimmer) {
country
}
}
}
assert DSL.execute(schema, query).data.success*.country.toUnique() == ['🇺🇸', '🇦🇺']打印自 2012 年伦敦奥运会以来的所有记录也与之前非常相似
DSL.execute(schema, '''{
allRecords {
at
event
}
}''').data.allRecords.each {
println "$it.at $it.event"
}neo4j-graphql-java
作为最后一个例子,让我们看看 neo4j-graphql-java 库提供的支持。它允许您将模式定义为字符串,如下所示
var schema = '''
type Swimmer {
name: String!
country: String!
}
type Swim {
who: Swimmer! @relation(name: "swam", direction: IN)
at: String!
result: String!
event: String!
time: Float
}
type Query {
success(at: String!): [Swim!]
}
'''
var graphql = new Translator(SchemaBuilder.buildSchema(schema))有趣的部分是您可以注释您的模式,例如 who 字段的 @relation 子句,它声明此字段对应于我们的 swam 边。
这意味着我们实际上不需要为该字段定义提供程序。它是如何工作的?该库将您的 GraphQL 查询转换为 Cypher 查询。
我们可以这样执行
var cypher = graphql.translate('''
query success($at: String!) {
success(at: $at) {
who {
country
}
}
}
''', [at: 'Paris 2024'])
var (q, p) = [cypher.query.first(), cypher.params.first()]
assert tx.execute(q, p)*.success*.who*.country.toUnique() == ['🇺🇸', '🇦🇺']我们只展示了我们的一个查询,但我们可以以类似的方式涵盖其他查询。
静态类型
另一个有趣的话题是改进图数据库代码的类型检查。Groovy 支持从非常动态的代码风格到“比 Java 更强”的类型检查。
有些图数据库技术只提供无模式体验,以允许您的数据模型“轻松适应业务变化”。其他则允许定义具有不同程度信息的模式。Groovy 的动态功能使其特别适合编写即使您动态更改数据模型也能轻松工作的代码。但是,如果您更喜欢在代码中添加进一步的类型检查,Groovy 也提供了选项。
让我们回顾一下我们的示例使用了哪些类似模式的功能
-
Apache TinkerPop:使用动态顶点标签和边
-
Neo4j:使用动态顶点标签,但要求边由枚举定义
-
Apache AGE:虽然本文未展示,但定义了顶点标签,边是动态的
-
OrientDB:定义了顶点和边类
-
ArcadeDB:定义了顶点和边类型
-
TuGraph:定义了顶点和边标签,顶点标签具有类型化属性,边标签使用 from/to 顶点标签进行类型化
-
Apache HugeGraph:定义了顶点和边标签,顶点标签具有类型化属性,边标签使用 from/to 顶点标签进行类型化
我们选择非常动态的选项的好处是,我们可以轻松添加新的顶点和边,例如
var mb = g.addV('Coach').property(name: 'Michael Bohl').next()
mb.coaches(kmk)对于使用类似模式功能的示例,我们需要先声明额外的顶点类型 Coach 和边 coaches,然后才能定义新的节点和边。让我们只探讨 Groovy 功能可以更容易处理类型化的一些选项。
我们之前使用了 insertSwimmer 和 insertSwim 辅助方法。即使我们的底层数据库技术没有使用它们,我们也可以为这些参数提供类型。这将至少在将信息插入图中时捕获类型错误。
我们可以使用 Groovy 类或记录的富类型域。我们可以生成必要的方法调用来创建模式/标签,然后填充数据库。
或者,我们可以保持代码的动态形式,并利用 Groovy 可扩展的类型检查系统。我们可以编写一个扩展,如果检测到任何无效的边或顶点定义,则编译失败。对于我们上面 coaches 的例子,前一行将通过编译,但如果该边关系有不正确的顶点,编译将失败,例如对于语句 swim1.coaches(mb),我们将得到以下错误
[Static type checking] - Invalid edge - expected: <Coach>.coaches(<Swimmer>) but found: <Swim>.coaches(<Coach>) @ line 20, column 5. swim1.coaches(mb) ^ 1 error
我们不会展示这段代码,它在 GitHub 仓库中。它是硬编码以了解 coaches 关系的。理想情况下,我们会将可扩展类型检查与前面提到的富类型模型结合起来,并且我们可以填充类型检查器所需的信息以及图数据库所需的任何标签/模式信息。
无论如何,这些只是 Groovy 提供给您的一些选项。何不自己尝试一些想法,享受其中的乐趣!