
使用组合和排列进行 Groovy™ 测试
发布时间:2023-03-19 下午 05:23
这篇博文的灵感来自最近 foojay.io 的文章《使用组合、排列和乘积进行详尽的 JUnit5 测试》,作者 Per Minborg 探讨了如何进行更详尽的测试,重点是使用 Chronicle 测试框架。让我们看看如何将该框架和其他框架与 Groovy 一起使用。为了好玩,我们还会加入一些配对测试和基于属性的测试。
Chronicle 测试框架
Chronicle 测试框架是一个与 JUnit 配合使用的库,支持轻松测试数据或动作的组合和排列。可能最容易通过示例来解释它的工作原理。前面提到的博客有一个示例,展示了如何计算排列
@Test
void numberOfPermutations() {
assert Combination.of(1, 2, 3, 4, 5, 6)
.flatMap(Permutation::of)
.peek{ println it }
.count() == 1957
}我们稍微调整了一下,用 `peek` 打印出排列。输出如下所示(为简洁起见,省略了几个部分)
[] [1] [2] [3] [4] [5] [6] [1, 2] [2, 1] [1, 3] ... [5, 6] [6, 5] [1, 2, 3] [1, 3, 2] ... [6, 5, 4, 3, 1, 2] [6, 5, 4, 3, 2, 1]
如果我们的测试场景需要数字列表,上面生成的列表可能非常完美,我们无需创建 1957 个单独的手动测试,那将是一种费力且脆弱的替代方案!
我们应该注意到 Groovy 内置了一些很好的组合和排列功能。Groovy 默认不包括排列中的空情况,但我们可以很容易地自己添加。这是一种在 Groovy 中编写上述测试而无需任何额外依赖的方法
@Test
void numberOfPermutations() {
var perms = (1..6).subsequences()*.permutations().sum() << []
assert perms.size() == 1957
}稍后我们将看到更多 Chronicle 测试框架和 Groovy 内置功能的示例。
测试场景
有关更多背景信息,我们鼓励您阅读原始文章。我们将使用相同的两个场景,涉及测试列表上的操作序列,以确保列表的行为方式相同。这两个场景(尽管我们主要关注第一个)是
-
我们将比较 `LinkedList` 和 `ArrayList` 类,在这两个类上执行一系列变异操作,例如 `clear`、`add` 和 `remove`,并检查我们是否得到相同的结果。
-
我们将扩展第一个场景,以涵盖更广泛的列表,包括 `CopyOnWriteArrayList`、`Stack` 和 `Vector`。
使用 Chronicle 测试框架的场景 1
我们首先创建一个谓词来测试奇数,因为我们的一个操作需要它。然后我们创建我们想要在列表上执行的操作列表。
final Predicate<Integer> ODD = n -> n % 2 == 1
final OPERATIONS = [
NamedConsumer.of(List::clear, "clear()"),
NamedConsumer.of(list -> list.add(1), "add(1)"),
NamedConsumer.of(list -> list.removeElement(1), "remove(1)"),
NamedConsumer.of(list -> list.addAll(Arrays.asList(2, 3, 4, 5)), "addAll(2,3,4,5)"),
NamedConsumer.of(list -> list.removeIf(ODD), "removeIf(ODD)")
]这与之前博客中显示的 Java 版本非常相似,但有一个细微的改动。我们使用了 Groovy 的 `removeElement` 方法,它是 `remove` 的别名。
|
注意
|
Java 有两个重载的 `remove` 方法,一个用于从列表中删除第一个元素(如果找到),另一个用于删除特定索引处的元素。处理整数列表时,有时(如原始博客所示)需要使用类型转换来消除这两个变体之间的歧义。Groovy 也适用于相同的类型转换技巧,但也提供了 `removeElement` 和 `remoteAt` 别名作为消除歧义的替代选择。稍后我们将看到 `removeAt` 的示例。 |
现在我们可以定义我们的测试了
@TestFactory
Stream<DynamicTest> validate() {
DynamicTest.stream(Combination.of(OPERATIONS)
.flatMap(Permutation::of),
FormatHelper::toString,
operations -> {
ArrayList first = []
LinkedList second = []
operations.forEach { op ->
op.accept(first)
op.accept(second)
}
assert first == second
})
}这会为我们操作的所有排列生成测试用例。对于每个测试用例,我们检查一旦我们应用了当前排列中的所有操作,两个列表是否具有相同的内容。
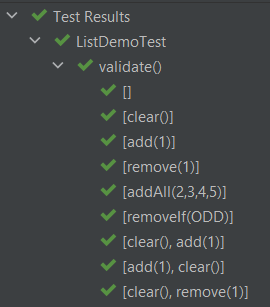
如果您想知道为什么我们之前在定义 `OPERATIONS` 时使用了 `NamedConsumer`,那是因为当测试使用各种 JUnit5 感知测试运行器运行时,它支持友好的测试名称。以下是在 IntelliJ IDEA 中运行测试时显示的前 9 个(共 326 个)测试
使用 Chronicle 测试框架的场景 2
对于此场景,我们希望比较更多列表类型之间的结果。同样,我们可以手动创建上述测试的额外变体,以满足附加列表类型之间的比较,但为什么不生成这些变体而无需额外的手动工作呢。
为此,我们创建了一个工厂列表,用于生成我们感兴趣的列表
final CONSTRUCTORS = [
ArrayList, LinkedList, CopyOnWriteArrayList, Stack, Vector
].collect(clazz -> clazz::new as Supplier)我们现在可以创建一个与原始博客类似的测试,该测试在所有列表上运行所有操作的排列,然后检查每个列表组合以确保结果列表相等
@TestFactory
Stream<DynamicTest> validateMany() {
DynamicTest.stream(Combination.of(OPERATIONS)
.flatMap(Permutation::of),
FormatHelper::toString,
operations -> {
var lists = CONSTRUCTORS.stream()
.map(Supplier::get)
.toList()
operations.forEach(lists::forEach)
Combination.of(lists)
.filter(set -> set.size() == 2)
.map(ArrayList::new)
.forEach { p1, p2 -> assert p1 == p2 }
})
}我们可以通过这样的测试来检查我们的不同列表组合是否正确生成
@Test
void numberOfPairCombinations() {
assert Combination.of(CONSTRUCTORS)
.filter(l -> l.size() == 2)
.peek { println it*.get()*.class*.simpleName }
.count() == 10
}我们可以看到有 10 对具有以下类型
[ArrayList, LinkedList] [ArrayList, CopyOnWriteArrayList] [ArrayList, Stack] [ArrayList, Vector] [LinkedList, CopyOnWriteArrayList] [LinkedList, Stack] [LinkedList, Vector] [CopyOnWriteArrayList, Stack] [CopyOnWriteArrayList, Vector] [Stack, Vector]
此时,原始博客继续警告在许多维度或情况下计算排列时可能出现指数级大量测试用例的问题。我们稍后会再讨论这个问题,但首先让我们看看使用原生 Groovy 的这两个场景的类似测试。
使用原生 Groovy 和 JUnit5 的场景 1
我们创建操作列表
final OPERATIONS = [
List::clear,
{ list -> list.add(1) },
{ list -> list.removeElement(1) },
{ list -> list.addAll(Arrays.asList(2, 3, 4, 5)) },
{ list -> list.removeIf(ODD) }
]现在我们使用 Groovy 的 `eachPermutation` 方法遍历不同的排列
@Test
void validate() {
OPERATIONS.eachPermutation { opList ->
ArrayList first = []
LinkedList second = []
opList.each { op ->
op(first)
op(second)
}
assert first == second
}
}使用原生 Groovy 和 JUnit5 的场景 2
使用与之前相同的 `OPERATIONS` 和 `CONSTRUCTORS` 定义,我们可以将测试编写如下
@Test
void validateMany() {
OPERATIONS.eachPermutation { opList ->
def pairs = CONSTRUCTORS*.get().subsequences().findAll { it.size() == 2 }
pairs.each { first, second ->
opList.each { op ->
op(first)
op(second)
}
assert first == second
}
}
}我们可以像以前一样,以类似的方式再次检查列表类型
@Test
void numberOfPairCombinations() {
assert (1..5).subsequences()
.findAll(l -> l.size() == 2)
.size() == 10
}同样,有 10 种配对组合。
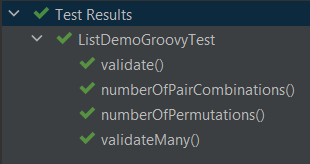
Groovy 版本不需要额外的依赖项,但有一个区别。嵌套结果的漂亮格式缺失了。IntelliJ 中 JUnit5 的运行将如下所示
我们无法深入到 `validate` 和 `validateMany` 测试中的不同测试子用例。让我们将该功能与原生 Groovy 和 Spock 结合起来。我们只展示场景 1 的方法,但如果需要,同样的技术也可以用于场景 2。
使用数据驱动测试和 JUnit5 的场景 1
首先,我们将操作列表更改为地图,其中键是我们在使用 `NamedConsumer` 时看到的“名称”
final OPERATIONS = [
'clear()' : List::clear,
'add(1)' : { list -> list.add(1) },
'remove(1)' : { list -> list.removeElement(1) },
'addAll(2,3,4,5)': { list -> list.addAll(Arrays.asList(2, 3, 4, 5)) },
'removeIf(ODD)' : { list -> list.removeIf(ODD) }
]现在,我们将创建一个辅助方法来生成我们的排列,包括友好的名称和操作
Stream<Arguments> operationPermutations() {
OPERATIONS.entrySet().permutations().collect(e -> Arguments.of(e.key, e.value)).stream()
}有了这些,我们就可以更改测试以使用 JUnit5 的数据驱动 `ParameterizedTest` 功能
@ParameterizedTest(name = "{index} {0}")
@MethodSource("operationPermutations")
void validate(List<String> names, List<Closure> operations) {
ArrayList first = []
LinkedList second = []
operations.each { op ->
op(first)
op(second)
}
assert first == second
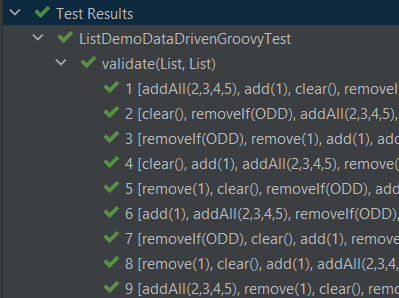
}其输出如下
使用 Spock 的场景 1
我们还想展示另一个有用的框架,即 Spock 测试框架,它也支持数据驱动测试。
Spock 支持多种不同的测试风格。在这里,我们使用“给定”、“当”、“然后”风格,并使用“where”子句进行数据驱动测试
def "[#iterationIndex] #names"(List<String> names, List<Closure> operations) {
given:
ArrayList first = []
LinkedList second = []
when:
operations.each { op ->
op(first)
op(second)
}
then:
first == second
where:
entries << OPERATIONS.entrySet().permutations()
(names, operations) = entries.collect{ [it.key, it.value] }.transpose()
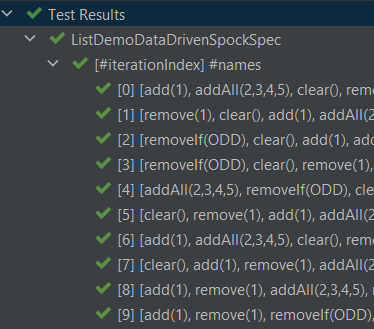
}运行时,它有以下输出
现在我们来介绍一些其他主题。
所有对
原帖中的“最终警告”是要警惕使用组合和排列时可能出现的测试用例数量的潜在爆炸。
配对测试的概念是一种旨在帮助限制这种情况爆发的技术。它依赖于这样一个事实:许多错误会在两个功能发生不良交互时浮出水面。如果我们有一个涉及五个功能的测试,那么也许我们不需要所有五个功能的每个组合。通过示例更容易理解。
让我们添加更多操作,然后将它们分成三组:*增长*、*收缩*和*读取*操作。
final GROW_OPS = [
'add(1)': { list -> list.add(1) },
'addAll([2, 3, 4, 5])': { list -> list.addAll([2, 3, 4, 5]) },
'maybe add(1)': { list -> if (new Random().nextBoolean()) list.add(1) },
].entrySet().toList()
final SHRINK_OPS = [
'clear()': List::clear,
'remove(1)': { list -> list.removeElement(1) },
'removeIf(ODD)': { list -> list.removeIf(ODD) }
].entrySet().toList()
final READ_OPS = [
'isEmpty()': List::isEmpty,
'size()': List::size,
'contains(1)': { list -> list.contains(1) },
].entrySet().toList()我们希望测试用例执行一个*增长*操作,然后是一个*收缩*操作,然后是一个*读取*操作。如果我们想涵盖所有可能的组合,我们需要 27 个测试用例
assert [ADD_OPS, REMOVE_OPS, READ_OPS].combinations().size() == 27许多语言都有各种全对库。我们将使用适用于 Java 的 AllPairs4J 库。
该库有一个构建器,我们可以在其中指定感兴趣的参数,然后它会生成配对组合。我们像之前一样对每个组合进行类似的测试
@Test
void validate() {
var allPairs = new AllPairs.AllPairsBuilder()
.withTestCombinationSize(2)
.withParameter(new Parameter("Add op", ADD_OPS))
.withParameter(new Parameter("Remove op", REMOVE_OPS))
.withParameter(new Parameter("Read op", READ_OPS))
.build()
allPairs.eachWithIndex { namedOps, index ->
print "$index: "
ArrayList first = []
LinkedList second = []
var log = []
namedOps.each{ k, v ->
log << "$k=$v.key"
var op = v.value
op(first)
op(second)
}
println log.join(', ')
assert first == second
}
}我们使用了 `withTestCombinationSize(2)` 来创建配对组合,但如果我们需要,该库支持 n 对。我们还使用了一个简单的手动构建日志,以便更容易理解正在发生的事情,但如果需要,我们可以利用我们之前在 JUnit5 和 Spock 中看到的数据驱动集成点。
当我们运行此测试时,它具有以下输出
1: Add op=add(1), Remove op=clear(), Read op=isEmpty() 2: Add op=maybe add(1), Remove op=remove(1), Read op=isEmpty() 3: Add op=addAll([2, 3, 4, 5]), Remove op=removeIf(ODD), Read op=isEmpty() 4: Add op=addAll([2, 3, 4, 5]), Remove op=remove(1), Read op=size() 5: Add op=maybe add(1), Remove op=clear(), Read op=size() 6: Add op=add(1), Remove op=removeIf(ODD), Read op=size() 7: Add op=add(1), Remove op=remove(1), Read op=contains(1) 8: Add op=maybe add(1), Remove op=removeIf(ODD), Read op=contains(1) 9: Add op=addAll([2, 3, 4, 5]), Remove op=clear(), Read op=contains(1)
您可以看到只生成了 9 个测试,而不是详尽测试所需的 27 个组合。要了解正在发生什么,我们需要进一步检查输出。
如果我们只看 `add(1)` *Add operation*,我们会看到所有三个 *Remove operations* 和所有三个 *Read operations* 都包含在测试中
1: Add op=add(1), Remove op=clear(), Read op=isEmpty() 2: Add op=maybe add(1), Remove op=remove(1), Read op=isEmpty() 3: Add op=addAll([2, 3, 4, 5]), Remove op=removeIf(ODD), Read op=isEmpty() 4: Add op=addAll([2, 3, 4, 5]), Remove op=remove(1), Read op=size() 5: Add op=maybe add(1), Remove op=clear(), Read op=size() 6: Add op=add(1), Remove op=removeIf(ODD), Read op=size() 7: Add op=add(1), Remove op=remove(1), Read op=contains(1) 8: Add op=maybe add(1), Remove op=removeIf(ODD), Read op=contains(1) 9: Add op=addAll([2, 3, 4, 5]), Remove op=clear(), Read op=contains(1)
如果我们只看 `maybe add(1)` *Add operation*,我们会看到所有三个 *Remove operations* 和所有三个 *Read operations* 都被覆盖
1: Add op=add(1), Remove op=clear(), Read op=isEmpty() 2: Add op=maybe add(1), Remove op=remove(1), Read op=isEmpty() 3: Add op=addAll([2, 3, 4, 5]), Remove op=removeIf(ODD), Read op=isEmpty() 4: Add op=addAll([2, 3, 4, 5]), Remove op=remove(1), Read op=size() 5: Add op=maybe add(1), Remove op=clear(), Read op=size() 6: Add op=add(1), Remove op=removeIf(ODD), Read op=size() 7: Add op=add(1), Remove op=remove(1), Read op=contains(1) 8: Add op=maybe add(1), Remove op=removeIf(ODD), Read op=contains(1) 9: Add op=addAll([2, 3, 4, 5]), Remove op=clear(), Read op=contains(1)
如果我们只看 `addAll([2, 3, 4, 5])` *Add operation*,我们将再次看到所有三个 *Remove operations* 和所有三个 *Read operations* 都被覆盖
1: Add op=add(1), Remove op=clear(), Read op=isEmpty() 2: Add op=maybe add(1), Remove op=remove(1), Read op=isEmpty() 3: Add op=addAll([2, 3, 4, 5]), Remove op=removeIf(ODD), Read op=isEmpty() 4: Add op=addAll([2, 3, 4, 5]), Remove op=remove(1), Read op=size() 5: Add op=maybe add(1), Remove op=clear(), Read op=size() 6: Add op=add(1), Remove op=removeIf(ODD), Read op=size() 7: Add op=add(1), Remove op=remove(1), Read op=contains(1) 8: Add op=maybe add(1), Remove op=removeIf(ODD), Read op=contains(1) 9: Add op=addAll([2, 3, 4, 5]), Remove op=clear(), Read op=contains(1)
你可能会想,通过将测试数量从 27 个减少到 9 个,我们是否降低了发现 bug 的机会?如果 bug 是由两个功能的不良交互引起的,那么不会,我们仍然涵盖了所有情况。这并非总是如此,因为一些晦涩的 bug 可能是两个以上功能交互的结果。因此,该库支持 n 对测试。本质上,这种技术允许你平衡组合测试的爆炸式增长与发现更晦涩 bug 的机会。
让我们快速交叉检查一下,以增加对我们 9 个测试用例的信心。
首先,我们将调整测试以捕获异常并在该点打印出我们手工制作的日志。这只是我们处理此类异常的一种方式
namedOps.each{ k, v ->
try {
log << "$k=$v.key"
var op = v.value
op(first)
op(second)
} catch(ex) {
println 'Failed on last op of: ' + log.join(', ')
throw ex
}
}现在,让我们故意引入一个错误。我们将第二个*收缩*操作替换为尝试删除索引 0 处的元素(假设至少有一个元素)
final SHRINK_OPS = [
'clear()': List::clear,
// 'remove(1)': { list -> list.removeElement(1) }, // (1)
'removeAt(0)': { list -> list.removeAt(0) }, // (2)
'removeIf(ODD)': { list -> list.removeIf(ODD) }
].entrySet().toList()-
注释掉此操作
-
添加此有问题的操作
现在,当我们运行测试时,我们看到
> Task :test FAILED 0: Grow op=add(1), Shrink op=clear(), Read op=isEmpty() 1: Grow op=addAll([2, 3, 4, 5]), Shrink op=removeAt(0), Read op=isEmpty() 2: Grow op=maybe add(1), Shrink op=removeIf(ODD), Read op=isEmpty() 3: Failed on last op of: Grow op=maybe add(1), Shrink op=removeAt(0)
在这里我们可以看到案例 0、1 和 2 成功了。对于案例 3,增长操作,它一半时间随机添加一个元素,必须没有添加任何东西,随后尝试删除第一个元素失败。因此,即使我们的测试用例数量很少,也检测到了这个“bug”。
Jqwik
我们的最后一个示例着眼于基于属性的测试和 jqwik 库。
基于属性的测试工具也试图做比手动测试更容易完成(和维护)的更多测试,但它们本身并不专注于完全详尽的测试。相反,它们专注于生成随机测试输入,然后检查某些属性是否成立。
支持*有状态*基于属性的测试的框架还允许您生成随机命令,我们可以在有状态系统上发布这些命令,然后检查某些属性是否成立。
我们将以这种方式使用 jqwik 的有状态测试功能。
我们从一个类似的操作(和友好的名称)映射开始,就像我们之前看到的那样
final OPERATIONS = [
'clear()' : List::clear,
'add(1)' : { list -> list.add(1) },
'remove(1)' : { list -> list.removeElement(1) },
'addAll(2,3,4,5)': { list -> list.addAll(Arrays.asList(2, 3, 4, 5)) },
'removeIf(ODD)' : { list -> list.removeIf(ODD) }
].entrySet().toList()jqwik 中的有状态测试功能具有动作链的概念,它描述了有状态对象如何转换。在我们的例子中,我们随机选择一个操作,然后将所选操作应用于两个列表,并检查列表是否包含相同的值
class MutateAction implements Action.Independent<Tuple2<List, List>> {
Arbitrary<Transformer<Tuple2<List, List>>> transformer() {
Arbitraries.of(OPERATIONS).map(operation ->
Transformer.mutate(operation.key) { list1, list2 ->
var op = operation.value
op(list1)
op(list2)
assert list1 == list2
})
}
}现在我们指定我们希望动作链中最多有 6 个操作,并且我们将从一个 ArrayList 和一个 LinkedList 开始,两者都包含一个元素,即整数 1
@Provide
Arbitrary<ActionChain> myListActions() {
ActionChain.startWith{ Tuple2.tuple([1] as ArrayList, [1] as LinkedList) }
.withAction(new MutateAction())
.withMaxTransformations(6)
}@Provide 注解表示此方法可用于为需要动作链的测试提供输入。
最后,我们添加了测试。对于 jqwik,这是使用 @Property 注解完成的
@Property(seed='100001')
void confirmSimilarListBehavior(@ForAll("myListActions") ActionChain chain) {
chain.run()
}“seed”注解属性是可选的,可用于获得可重复的测试。
当我们运行此测试时,我们会看到 jqwik 生成了 1000 个不同的操作序列,并且它们都通过了
|-----------------------jqwik----------------------- tries = 1000 | # of calls to property checks = 1000 | # of not rejected calls generation = RANDOMIZED | parameters are randomly generated after-failure = SAMPLE_FIRST | try previously failed sample, then previous seed when-fixed-seed = ALLOW | fixing the random seed is allowed edge-cases#mode = MIXIN | edge cases are mixed in edge-cases#total = 0 | # of all combined edge cases edge-cases#tried = 0 | # of edge cases tried in current run seed = 100001 | random seed to reproduce generated values
和以前一样,我们可以故意破坏代码,以说服自己我们的测试正在发挥作用。让我们重新引入我们用于全对测试的有问题的 `removeAt` 操作
final OPERATIONS = [
'clear()' : List::clear,
'add(1)' : { list -> list.add(1) },
// 'remove(1)' : { list -> list.removeElement(1) }, // (1)
'removeAt(0)' : { list -> list.removeAt(0) }, // (2)
'addAll(2,3,4,5)': { list -> list.addAll(Arrays.asList(2, 3, 4, 5)) },
'removeIf(ODD)' : { list -> list.removeIf(ODD) }-
已注释掉
-
已添加可能中断的操作
当我们重新运行测试时,我们看到
ListDemoDataDrivenJqwikTest:confirmSimilarListBehavior =
org.opentest4j.AssertionFailedError:
Run failed after the following actions: [
clear()
removeAt(0)
]
final state: [[], []]
Index 0 out of bounds for length 0
|-----------------------jqwik-----------------------
tries = 4 | # of calls to property
checks = 4 | # of not rejected calls
generation = RANDOMIZED | parameters are randomly generated
after-failure = SAMPLE_FIRST | try previously failed sample, then previous seed
when-fixed-seed = ALLOW | fixing the random seed is allowed
edge-cases#mode = MIXIN | edge cases are mixed in
edge-cases#total = 0 | # of all combined edge cases
edge-cases#tried = 0 | # of edge cases tried in current run
seed = 100001 | random seed to reproduce generated values
...
Original Error
--------------
org.opentest4j.AssertionFailedError:
Run failed after the following actions: [
addAll(2,3,4,5)
add(1)
clear()
removeAt(0)
]
final state: [[], []]
Index 0 out of bounds for length 0
此输出中有几点需要解释
-
它生成了一个“收缩”序列,其中包含 `clear()` 和 `removeAt(0)` 操作,表现出错误。这是一个预期错误。
-
在第 4 次检查失败之前,它运行了 3 个成功的其他随机序列。
-
收缩前生成的序列是 `addAll(2,3,4,5)`、`add(1)`、`clear()` 和 `removeAt(0)`。
Java 使用
您还可以从 Java 中使用 Groovy 的排列和组合功能,如下面的测试所示
@Test // Java
public void combinations() {
String[] letters = {"A", "B"};
Integer[] numbers = {1, 2};
Object[] collections = {letters, numbers};
var expected = List.of(
List.of("A", 1),
List.of("B", 1),
List.of("A", 2),
List.of("B", 2)
);
var combos = GroovyCollections.combinations(collections);
assertEquals(expected, combos);
}
@Test
public void subsequences() {
var numbers = List.of(1, 2, 3);
var expected = Set.of(
List.of(1), List.of(2), List.of(3),
List.of(1, 2), List.of(1, 3), List.of(2, 3),
List.of(1, 2, 3)
);
var result = GroovyCollections.subsequences(numbers);
assertEquals(expected, result);
}
@Test
public void permutations() {
var numbers = List.of(1, 2, 3);
var gen = new PermutationGenerator<>(numbers);
var result = new HashSet<>();
while (gen.hasNext()) {
List<Integer> next = gen.next();
result.add(next);
}
var expected = Set.of(
List.of(1, 2, 3), List.of(1, 3, 2),
List.of(2, 1, 3), List.of(2, 3, 1),
List.of(3, 1, 2), List.of(3, 2, 1)
);
assertEquals(expected, result);
}