
处理环法多芬赛结果
作者: Paul King
发布时间:2023-06-13 05:00PM
2023 年环多菲内赛刚刚结束。让我们使用 Groovy 和 DuckDB 来分析比赛结果。本文中,我们关注的是总成绩排名前十的选手。
结果文件
我们的结果存储在一个 CSV 文件中
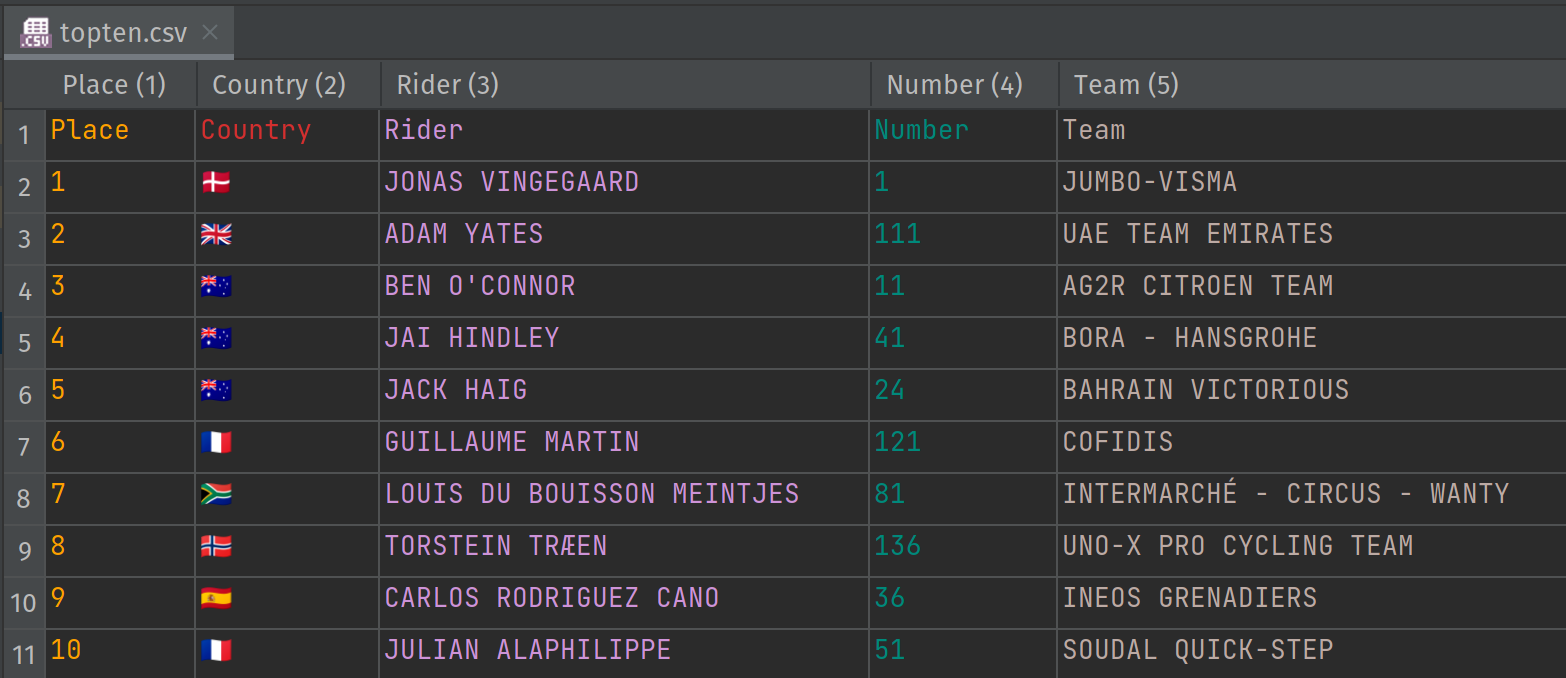
我们的目标非常简单,只需打印出信息,但按每个选手的国家分组。
Sql.withInstance('jdbc:duckdb:', 'org.duckdb.DuckDBDriver') { sql ->
println "Country Riders Places Count"
sql.eachRow("""SELECT Country,
rpad(string_agg(Rider, ', '), 40, ' ') as Riders,
rpad(string_agg(Place, ', '), 10, ' ') as Places,
bar(count(Country), 0, 4, 30) as Count
FROM 'topten.csv' GROUP BY Country""") { row ->
row.with {
println "$Country $Riders$Places$Count"
}
}
}在这里,我们使用了 DuckDB 的几个内置函数,包括用于右填充输出的 rpad,用于聚合来自同一国家的选手(及其名次)的 string_agg,以及用于生成漂亮条形图的 bar。
运行此代码会产生以下输出
Country Riders Places Count
🇩🇰 JONAS VINGEGAARD 1 ███████▌
🇬🇧 ADAM YATES 2 ███████▌
🇦🇺 BEN O’CONNOR, JAI HINDLEY, JACK HAIG 3, 4, 5 ██████████████████████▌
🇫🇷 GUILLAUME MARTIN, JULIAN ALAPHILIPPE 6, 10 ███████████████
🇿🇦 LOUIS DU BOUISSON MEINTJES 7 ███████▌
🇳🇴 TORSTEIN TRÆEN 8 ███████▌
🇪🇸 CARLOS RODRIGUEZ CANO 9 ███████▌我们可以使用 GQuery (AKA GINQ) 通过以下代码实现类似的结果
var f = 'topten.csv' as File
var lines = f.readLines()*.split(',')
var cols = lines[0].size()
var rows = lines[1..-1].collect{row ->
(0..<cols).collectEntries{ col -> [lines[0][col], row[col]] }}
var commaDelimited = Collectors.joining(', ')
var aggRiders = { it.stream().map(rec -> rec.r.Rider).collect(commaDelimited) }
var aggPlaces = { it.stream().map(rec -> rec.r.Place).collect(commaDelimited) }
println GQ {
from r in rows
groupby r.Country
select r.Country,
agg(aggRiders(_g)) as Riders,
agg(aggPlaces(_g)) as Places,
'██' * count(r.Country) as Count
}我们可以使用 CSV 库读取数据,但对于这个简单的例子,我们只使用 Groovy 的行/文本处理功能。GQuery 目前没有内置的 bar 或 string_agg 等效函数,因此我们自己编写了粗略的条形字符函数和聚合器 aggRiders 和 aggPlaces。
运行此代码会产生以下输出
+---------+--------------------------------------+---------+--------+
| Country | Riders | Places | Count |
+---------+--------------------------------------+---------+--------+
| 🇦🇺 | BEN O’CONNOR, JAI HINDLEY, JACK HAIG | 3, 4, 5 | ██████ |
| 🇩🇰 | JONAS VINGEGAARD | 1 | ██ |
| 🇳🇴 | TORSTEIN TRÆEN | 8 | ██ |
| 🇿🇦 | LOUIS DU BOUISSON MEINTJES | 7 | ██ |
| 🇬🇧 | ADAM YATES | 2 | ██ |
| 🇪🇸 | CARLOS RODRIGUEZ CANO | 9 | ██ |
| 🇫🇷 | GUILLAUME MARTIN, JULIAN ALAPHILIPPE | 6, 10 | ████ |
+---------+--------------------------------------+---------+--------+