
使用 Groovy™ 读写 CSV 文件
发布时间:2022-07-25 02:26PM
简介
在这篇文章中,我们将探讨如何使用 Groovy 阅读和写入 CSV 文件。
CSV 文件不就是文本文件吗?
对于简单的情况,我们可以像处理其他文本文件一样处理 CSV 文件。假设我们有以下数据要写入 CSV 文件
def data = [
['place', 'firstname', 'lastname', 'team'],
['1', 'Lorena', 'Wiebes', 'Team DSM'],
['2', 'Marianne', 'Vos', 'Team Jumbo Visma'],
['3', 'Lotte', 'Kopecky', 'Team SD Worx']
]Groovy 使用类似于 Java 的 File 或 Path 对象。这里我们将使用一个 File 对象,并且为了我们的目的,我们只使用一个临时文件,因为我们只是要读回它并对照我们的数据进行检查。以下是创建临时文件的方法
def file = File.createTempFile('FemmesStage1Podium', '.csv')(在这个简单的例子中)写入我们的 CSV 文件就像用逗号连接数据,用行分隔符连接行一样简单
file.text = data*.join(',').join(System.lineSeparator())这里我们一次性“写入”了整个文件内容,但也有按行、按字符或按字节写入的选项。
读取数据也同样简单。我们读取行并按逗号分割
assert file.readLines()*.split(',') == data通常,我们可能希望进一步处理数据。Groovy 也提供了很好的选项。假设我们有以下现有 CSV 文件
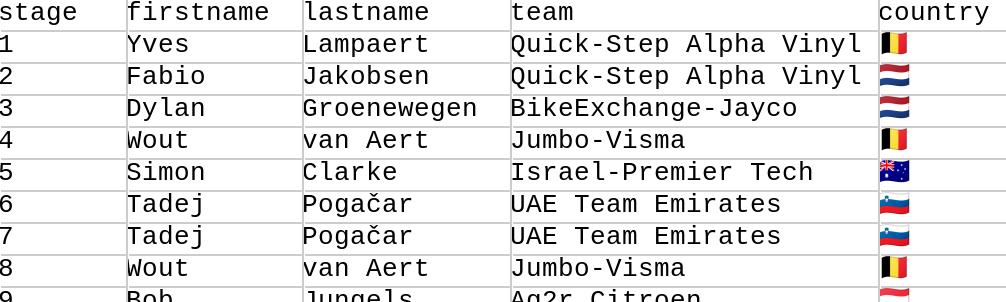
我们可以像下面的代码一样读取文件并选择感兴趣的各种列
def file = new File('HommesStageWinners.csv')
def rows = file.readLines().tail()*.split(',')
int total = rows.size()
Set names = rows.collect { it[1] + ' ' + it[2] }
Set teams = rows*.getAt(3)
Set countries = rows*.getAt(4)
String result = "Across $total stages, ${names.size()} riders from " +
"${teams.size()} teams and ${countries.size()} countries won stages."
assert result == 'Across 21 stages, 15 riders from 10 teams and 9 countries won stages.'在这里,tail() 方法跳过了标题行。第 0 列包含我们忽略的赛段编号。第 1 列包含名字,第 2 列包含姓氏,第 3 列包含车队,第 4 列包含车手的国家。我们将全名、车队和国家存储在集合中以去除重复项。然后我们使用这些集合的大小创建一条总体结果消息。
虽然对于这个简单的例子,编码相当简单,但不建议以这种方式手动处理 CSV 文件。CSV 的细节很快就会变得混乱。如果值本身包含逗号或换行符怎么办?也许我们可以用双引号括起来,但如果值包含双引号怎么办?依此类推。因此,建议使用 CSV 库。
我们稍后将介绍三个,但首先让我们通过查看多个获胜者来总结巡回赛的一些亮点。这是一些总结我们 CSV 数据的代码
def byValueDesc = { -it.value }
def bySize = { k, v -> [k, v.size()] }
def isMultiple = { it.value > 1 }
def multipleWins = { Closure select -> rows
.groupBy(select)
.collectEntries(bySize)
.findAll(isMultiple)
.sort(byValueDesc)
.entrySet()
.join(', ')
}
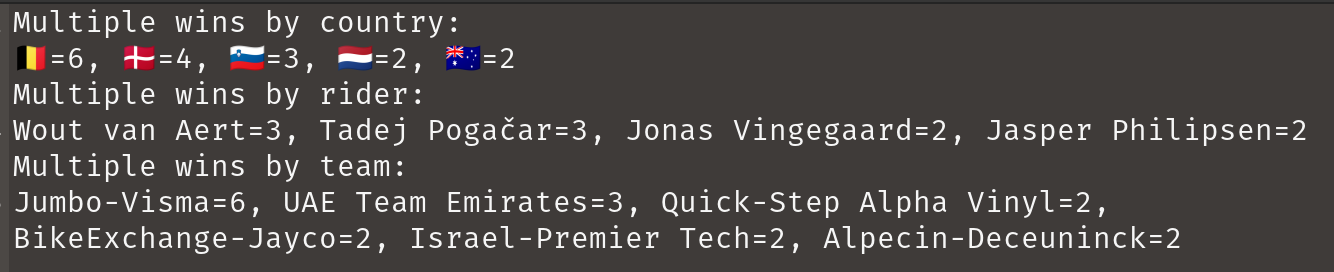
println 'Multiple wins by country:\n' + multipleWins{ it[4] }
println 'Multiple wins by rider:\n' + multipleWins{ it[1] + ' ' + it[2] }
println 'Multiple wins by team:\n' + multipleWins{ it[3] }这个摘要与 CSV 文件没有特别的关系,但是为了纪念巡回赛中精彩的骑行而总结的!这是输出
好的,现在让我们看看我们的三个 CSV 库。
Commons CSV
Apache Commons CSV 库使写入和解析 CSV 文件变得更容易。这是写入我们的 CSV 的代码,它使用了 CSVPrinter 类
file.withWriter { w ->
new CSVPrinter(w, CSVFormat.DEFAULT).printRecords(data)
}这是使用 RFC4180 解析器工厂单例读回它的代码
file.withReader { r ->
assert RFC4180.parse(r).records*.toList() == data
}还有其他用于制表符分隔值和其他常见格式的单例工厂以及构建器,可以让你设置各种选项,例如转义字符、引用选项、是否使用枚举来定义标题名称,以及是否忽略空行或空值。
对于我们更复杂的示例,我们还需要做一点工作。我们将使用构建器告诉解析器跳过标题行。我们本可以选择使用我们之前使用的 tail() 技巧,但我们决定改用解析器功能。代码如下所示
file.withReader { r ->
def rows = RFC4180.builder()
.setHeader()
.setSkipHeaderRecord(true)
.build()
.parse(r)
.records
assert rows.size() == 21
assert rows.collect { it.firstname + ' ' + it.lastname }.toSet().size() == 15
assert rows*.team.toSet().size() == 10
assert rows*.country.toSet().size() == 9
}您可以看到,在我们的处理过程中,我们使用了列名而不是列号。使用列名是使用 CSV 库的另一个优点;手动完成这方面的工作将相当麻烦。另请注意,为简单起见,我们没有像前面的示例那样创建完整的*结果*消息。相反,我们只检查了我们之前计算的所有相关集合的大小。
OpenCSV
OpenCSV 库在需要时处理混乱的 CSV 细节,但对于简单的情况不会造成阻碍。对于我们的第一个示例,CSVReader 和 CSVWriter 类将是合适的。这是以与之前相同的方式写入我们的 CSV 文件的代码
file.withWriter { w ->
new CSVWriter(w).writeAll(data.collect{ it as String[] })
}这是读取数据的代码
file.withReader { r ->
assert new CSVReader(r).readAll() == data
}如果我们查看生成的文件,它已经比之前更花哨,所有数据都用双引号括起来
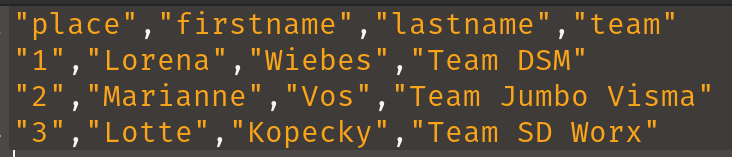
如果我们要进行更复杂的处理,CSVReaderHeaderAware 类会识别初始标题行及其列名。这是我们更复杂的示例,它进一步处理了一些数据
file.withReader { r ->
def rows = []
def reader = new CSVReaderHeaderAware(r)
while ((next = reader.readMap())) rows << next
assert rows.size() == 21
assert rows.collect { it.firstname + ' ' + it.lastname }.toSet().size() == 15
assert rows*.team.toSet().size() == 10
assert rows*.country.toSet().size() == 9
}您可以看到,在我们的处理过程中,我们再次使用了列名而不是列号。为简单起见,我们遵循了与 Commons CSV 示例相同的样式,只是检查了我们之前计算的所有相关集合的大小。
OpenCSV 还支持将 CSV 文件转换为 JavaBean 实例。首先,我们定义目标类(或注释现有域类)
class Cyclist {
@CsvBindByName(column = 'firstname')
String first
@CsvBindByName(column = 'lastname')
String last
@CsvBindByName
String team
@CsvBindByName
String country
}对于其中两列,我们已经指出 CSV 文件中的列名与我们的类属性不匹配。注释属性可以满足这种情况。
然后,我们可以使用此代码将我们的 CSV 文件转换为域对象列表
file.withReader { r ->
List<Cyclist> rows = new CsvToBeanBuilder(r).withType(Cyclist).build().parse()
assert rows.size() == 21
assert rows.collect { it.first + ' ' + it.last }.toSet().size() == 15
assert rows*.team.toSet().size() == 10
assert rows*.country.toSet().size() == 9
}OpenCSV 有许多我们没有展示的选项。写入文件时可以指定分隔符和引用字符,读取 CSV 时可以指定列位置、类型并验证数据。
Jackson Databind CSV
Jackson Databind 库支持 CSV 格式(以及许多其他格式)。
从现有数据写入 CSV 文件很简单,如这里的运行示例所示
file.withWriter { w ->
new CsvMapper().writeValue(w, data)
}这将数据写入我们的临时文件,正如我们在之前的示例中看到的那样。一个微小的区别是,默认情况下,只有包含空格的值会被双引号括起来,但与其他库一样,有许多配置选项可以调整这些设置。
可以使用以下代码读取数据
def mapper = new CsvMapper().readerForListOf(String).with(CsvParser.Feature.WRAP_AS_ARRAY)
file.withReader { r ->
assert mapper.readValues(r).readAll() == data
}我们更复杂的示例以类似的方式完成
def schema = CsvSchema.emptySchema().withHeader()
def mapper = new CsvMapper().readerForMapOf(String).with(schema)
file.withReader { r ->
def rows = mapper.readValues(r).readAll()
assert rows.size() == 21
assert rows.collect { it.firstname + ' ' + it.lastname }.toSet().size() == 15
assert rows*.team.toSet().size() == 10
assert rows*.country.toSet().size() == 9
}这里,我们告诉库利用我们的标题行并将每行数据存储在映射中。
Jackson Databind 还支持写入类,包括 JavaBean 和记录。让我们创建一个记录来保存我们的自行车手信息
@JsonCreator
record Cyclist(
@JsonProperty('stage') int stage,
@JsonProperty('firstname') String first,
@JsonProperty('lastname') String last,
@JsonProperty('team') String team,
@JsonProperty('country') String country) {
String full() { "$first $last" }
}请注意,我们再次可以指出记录组件名称可能与 CSV 文件中使用的名称不匹配的情况,我们只需在指定属性时提供替代名称即可。还有其他选项,例如指示字段是必需的或给出其列位置,但我们的示例不需要这些选项。我们还添加了一个 full() 辅助方法来返回自行车手的全名。
Groovy 将在支持它的平台上(JDK16+)使用本机记录,或在早期平台上模拟记录。
现在我们可以编写用于记录反序列化的代码了
def schema = CsvSchema.emptySchema().withHeader()
def mapper = new CsvMapper().readerFor(Cyclist).with(schema)
file.withReader { r ->
List<Cyclist> records = mapper.readValues(r).readAll()
assert records.size() == 21
assert records*.full().toSet().size() == 15
assert records*.team.toSet().size() == 10
assert records*.country.toSet().size() == 9
}结论
我们已经研究了将 CSV 文件写入字符串、域类和记录以及从它们读取。我们研究了手动处理简单情况,还研究了 OpenCSV、Commons CSV 和 Jackson Databind CSV 库。
使用 Groovy 进行数据科学的其他示例代码
https://github.com/paulk-asert/groovy-data-science