
Groovy™ 记录性能
发布时间:2023-05-09 11:39 PM (最后更新:2023-05-10 07:57 PM)
在 JEP Café 第 8 集中,José Paumard 探讨了与 Records 相关的多个主题,包括一些生成方法的性能,例如 hashCode 和 equals。它比较了 Java、Kotlin 数据类和 Lombok 的 @Data 类的这些方法的性能。
我们将进行类似的比较,并加入 Scala case class 和 Groovy record。对于 Groovy,我们将涵盖原生 record 和模拟 record(如果您仍然停留在旧版 JDK 上,可以在 JDK8 及更高版本中使用)。
我们的领域
我们将使用 JEP Café 节目中大约 7 分半钟的示例。它是五个字符串的聚合,它们共同形成一种聚合标签。
Java record
这是 Java 版本
public record JavaRecordLabel(String x0, String x1, String x2, String x3, String x4) { }带有 Lombok 的 @Data 的 Java 类
对于 Lombok,默认的等效代码将如下所示
@Data
public class LombokDataLabel {
final String x0, x1, x2, x3, x4;
}但是为了获得更接近 record 的行为,我们可以像这样以不同的方式配置 Lombok
@Data
@EqualsAndHashCode(doNotUseGetters = true)
public class LombokDirectDataLabel {
final String x0, x1, x2, x3, x4;
}我们稍后将更详细地讨论这一点。
Kotlin data class
这是 Kotlin 等效代码
data class KotlinDataLabel (
val x0: String, val x1: String, val x2: String, val x3: String, val x4: String)Scala case class
这是 Scala 等效代码
case class ScalaCaseLabel(x0: String, x1: String, x2: String, x3: String, x4: String)Groovy record
这是 Groovy 等效代码
record GroovyRecordLabel(String x0, String x1, String x2, String x3, String x4) { }当在支持 records 的 JDK 版本上运行时,这将生成类似于原生 Java record 的字节码。在早期 JDK 版本上,它将生成模拟 record。我们的示例将使用 JDK17。我们可以通过应用 record 选项注解来强制 Groovy 编译器使用 JDK17 生成模拟代码,如下所示
@RecordOptions(mode = RecordTypeMode.EMULATE)
record GroovyEmulatedRecordLabel(String x0, String x1, String x2, String x3, String x4) { }hashCode 的性能
我们的基准测试代码在所有情况下都用 Java 编写,并使用了 JMH。它调用了每个不同情况的静态实例的 hashCode 方法。完整的源代码位于 GitHub 上的 record-performance 存储库中。
这是设置静态实例的示例(X0 .. X4 是字符串常量)
private static final JavaRecordLabel JAVA_RECORD_LABEL = new JavaRecordLabel(X0, X1, X2, X3, X4);这是基准测试的示例
@Benchmark
public void hashcodeJavaRecord(Blackhole bh) {
bh.consume(JAVA_RECORD_LABEL.hashCode());
}我们使用了 3 次预热迭代和 10 次基准测试迭代
jmh {
warmupIterations = 3
iterations = 10
fork = 1
timeUnit = 'ns'
benchmarkMode = ['avgt']
}结果
测试是使用 GitHub actions 在各种平台上运行的。结果显示平均耗时(纳秒),因此 Score 越小表示越快。
使用 ubuntu-latest
Benchmark Mode Cnt Score Error Units HashCodeBenchmark.hashcodeGroovyEmulatedRecord avgt 10 3.130 ± 0.015 ns/op HashCodeBenchmark.hashcodeGroovyRecord avgt 10 2.814 ± 0.003 ns/op HashCodeBenchmark.hashcodeJavaRecord avgt 10 2.813 ± 0.001 ns/op HashCodeBenchmark.hashcodeKotlinDataLabel avgt 10 5.213 ± 0.016 ns/op HashCodeBenchmark.hashcodeLombokDirectDataLabel avgt 10 5.427 ± 0.071 ns/op HashCodeBenchmark.hashcodeLombokDataLabel avgt 10 18.328 ± 0.006 ns/op HashCodeBenchmark.hashcodeScalaCaseLabel avgt 10 16.901 ± 0.007 ns/op
使用 windows-latest
Benchmark Mode Cnt Score Error Units HashCodeBenchmark.hashcodeGroovyEmulatedRecord avgt 10 2.948 ± 0.005 ns/op HashCodeBenchmark.hashcodeGroovyRecord avgt 10 3.410 ± 0.005 ns/op HashCodeBenchmark.hashcodeJavaRecord avgt 10 3.407 ± 0.004 ns/op HashCodeBenchmark.hashcodeKotlinDataLabel avgt 10 6.635 ± 0.005 ns/op HashCodeBenchmark.hashcodeLombokDirectDataLabel avgt 10 8.520 ± 0.017 ns/op HashCodeBenchmark.hashcodeLombokDataLabel avgt 10 16.172 ± 0.026 ns/op HashCodeBenchmark.hashcodeScalaCaseLabel avgt 10 19.150 ± 0.048 ns/op
使用 macos-latest
Benchmark Mode Cnt Score Error Units HashCodeBenchmark.hashcodeGroovyEmulatedRecord avgt 10 2.999 ± 0.194 ns/op HashCodeBenchmark.hashcodeGroovyRecord avgt 10 2.765 ± 0.741 ns/op HashCodeBenchmark.hashcodeJavaRecord avgt 10 2.990 ± 0.280 ns/op HashCodeBenchmark.hashcodeKotlinDataLabel avgt 10 7.103 ± 0.123 ns/op HashCodeBenchmark.hashcodeLombokDirectDataLabel avgt 10 6.494 ± 0.063 ns/op HashCodeBenchmark.hashcodeLombokDataLabel avgt 10 15.100 ± 0.108 ns/op HashCodeBenchmark.hashcodeScalaCaseLabel avgt 10 20.327 ± 0.085 ns/op
结果图表
我们已经可以看到跨平台的结果存在一些差异。因此,让我们平均三个平台的结果,得到以下图表
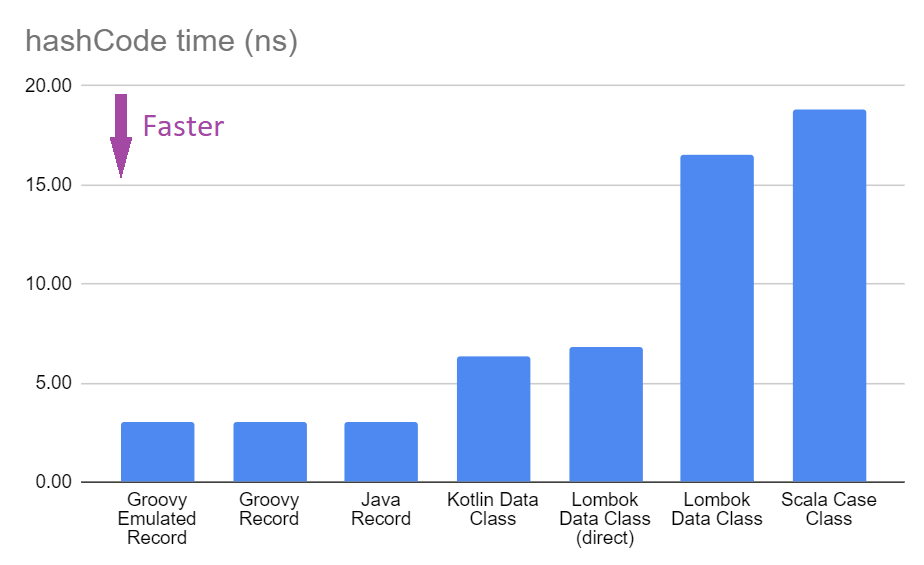
接下来我们将探讨这些差异背后的一些原因以及其他可以帮助您加快 hashCode 速度或证明为什么您可能希望选择较慢版本以换取其他有用属性的考虑因素。
讨论
从微基准测试中得出太多结论总是危险的。我们不总是知道我们是否在比较同类事物,或者在执行基准测试时机器上还运行着什么,或者稍微改变基准测试可能会如何改变结果。当然,对于 hashCode,结果受我们 record 组件的数量和类型的影响。即使是特定的数据实例(在我们的例子中是任意字符串)也会影响该方法的执行速度。
但这到底告诉了我们什么?对于 Groovy 用户来说,知道 hashCode 方法与 Java record 一样好甚至更好是件好事。这并不令人惊讶,因为 Groovy 字节码在 record 的大部分内容上与 Java 字节码几乎相同。
对于 Lombok 和其他语言,hashCode 方法较慢,但只慢几纳秒(或几十纳秒)。我们真的关心这个特定方法的速度有多快吗?当然,如果我们将大量标签实例存储到哈希集合中,这可能会很重要,但除此之外,则不那么重要;我们很少直接调用此方法。
但速度只是我们希望一个好的 hashCode 方法具备的属性之一。另一个是最小碰撞。毕竟,我们可以从 hashCode 返回常量 0 或 -1,这会非常快,但在碰撞方面却毫无希望。
哈希算法
对于 Scala case class,目前使用 Murmur3 哈希算法,它比 Java 使用的算法略慢,但 声称提高了碰撞抵抗力。如果您使用大型集合或具有许多组件的 record,这种权衡可能值得考虑。
您可以在 Groovy 中直接使用 Scala 的算法,如下所示的 record 定义
record GroovyRecordScalaMurmur3Label(String x0, String x1, String x2, String x3, String x4) {
int hashCode() {
ScalaRunTime._hashCode(new Tuple5<>(x0, x1, x2, x3, x4))
}
}这与我们之前条形图中的原生 Scala 示例的性能几乎相同。
如果您想要比 Scala 运行时 jar 更小的依赖项,您可以使用 Guava 中的 32 位 Murmur3 算法,或者编写自己的组合器来组合 Apache Commons Codec 的 Murmur3 算法在每个字符串组件的字节上生成的哈希值。在我的测试中,这两种替代方案最终都比借用 Scala 的算法慢,但我没有尝试优化我的实现。
如果您想深入探讨此主题,请查看
-
这篇关于 优化 HashMap 性能的精彩概述文章,
-
以及这篇关于 优化哈希策略及其对碰撞影响的文章,
-
Murmur3 算法的原始 C++ 实现。
JDK 版本支持
值得指出的一点是,Groovy、Lombok 和其他语言在早期 JDK 上也能工作。正如 GitHub action 工作流配置所示,这篇博客文章中的示例在 JDK 8、11 和 17 上进行了测试。
matrix:
java: [8,11,17]Java record 示例在 JDK 17 中进行测试(技术上要求 16+)。如果您停留在早期版本,了解这一点很好,但随着时间的推移,这应该会变得不那么重要。
缓存
Groovy 某些转换提供的一个不错的 Groovy 功能是缓存,这正是您可能希望对不可变类(如 records)执行的操作。实际上,在 Groovy 中,对于 @Immutable 类的 hashCode 和 toString 方法,默认情况下会启用缓存,但为了 Java 兼容性,我们默认关闭 record 的缓存。
让我们为 Groovy 中的 hashCode 方法启用缓存
@EqualsAndHashCode(useGetters = false, cache = true)
record GroovyRecordWithCacheLabel(String x0, String x1, String x2, String x3, String x4) { }默认情况下,Groovy record 的行为类似于 Java record。通过提供 @EqualsAndHashCode 注解,我们有效地获得了模拟 record 的代码,而不是正常的 record 字节码。为了尽可能接近 record 但启用缓存,我们启用 cache 并禁用 useGetters。我们将在下一小节中更详细地讨论后者。
现在,让我们更改 Java 和 Groovy 基准测试代码,以模拟多次使用 hashCode 的代码。出于我们的目的,我们只将 5 次对 hashCode 的调用求和
@Benchmark
public void hashcodeJavaRecord(Blackhole bh) {
bh.consume(JAVA_RECORD_LABEL.hashCode()
+ JAVA_RECORD_LABEL.hashCode()
+ JAVA_RECORD_LABEL.hashCode()
+ JAVA_RECORD_LABEL.hashCode()
+ JAVA_RECORD_LABEL.hashCode());
}我们也可以对 Groovy 执行相同的操作。这是我们新基准测试的结果
Benchmark Mode Cnt Score Error Units HashCodeCacheBenchmark.hashcodeGroovyCacheRecord avgt 10 4.296 ± 0.108 ns/op windows-latest HashCodeCacheBenchmark.hashcodeGroovyCacheRecord avgt 10 4.787 ± 0.151 ns/op ubuntu-latest HashCodeCacheBenchmark.hashcodeGroovyCacheRecord avgt 10 5.465 ± 0.045 ns/op macos-latest HashCodeCacheBenchmark.hashcodeJavaRecord avgt 10 21.956 ± 0.023 ns/op windows-latest HashCodeCacheBenchmark.hashcodeJavaRecord avgt 10 33.820 ± 0.750 ns/op ubuntu-latest HashCodeCacheBenchmark.hashcodeJavaRecord avgt 10 32.837 ± 1.136 ns/op macos-latest
正如所料,缓存的效果清晰可见。我们当然可以在 Java 中使用显式 hashCode 方法编写自己的缓存,并且可能会调用 Objects.hash 或类似方法,但这不如拥有声明式方法的选项那么好。
顺便说一句,我们可以在之前的 GroovyRecordScalaMurmur3Label 示例中的 hashCode 方法上添加 @Memoized,以便在使用该算法时启用缓存。
支持 JavaBean 类似行为
Java(和 Groovy)record 的另一个“功能”是能够覆盖 record 组件的“getter”。例如,您可以在 Java 中编写一个 3 字符串标签 record,该 record 始终以大写形式返回其 x1 组件
public record JavaRecordLabelUpper(String x0, String x1, String x2) {
public String x1() { return x1.toUpperCase(); }
}现在使用 x1() getter 方法将为您提供大写版本。请注意,hashCode(和 equals)不使用 getter,而是直接访问字段。
因此,虽然在以下示例中所有组件可能相等,但哈希码(以及整个 record)将不相等
private static final JavaRecordLabelUpper JAVA_UPPER_1
= new JavaRecordLabelUpper("a", "b", "c");
private static final JavaRecordLabelUpper JAVA_UPPER_2
= new JavaRecordLabelUpper("a", "B", "c");
...
assertEquals(JAVA_UPPER_1.x0(), JAVA_UPPER_2.x0());
assertEquals(JAVA_UPPER_1.x1(), JAVA_UPPER_2.x1());
assertEquals(JAVA_UPPER_1.x2(), JAVA_UPPER_2.x2());
assertNotEquals(JAVA_UPPER_1.hashCode(), JAVA_UPPER_2.hashCode());
assertNotEquals(JAVA_UPPER_1, JAVA_UPPER_2);这完全符合 JLS 规范中与 record 相关的部分所预期,并且鉴于 record 正在处理“简单值聚合”的用例,这是一个合理的设计决策。事实上,record 摆脱了许多 JavaBean 约定,因此我们可能会预期一些差异,但有些人士可能仍然觉得不使用 getter 很奇怪。
JLS 规范进一步阐述,指出上述 JavaRecordLabelUpper 类可能被认为是糟糕的风格。其理由是,从 record r1 的组件派生出的 record r2:
R r2 = new R(r1.c1(), r1.c2(), ..., r1.cn());对于任何行为良好的 record 类,r1.equals(r2) 都应该为 true,而对于 JavaRecordLabelUpper 则不会。
通过 getter 访问组件会更慢,但会保留上述属性。LombokDataLabel 和 ScalaCaseLabel 的实现都使用了 getter。这解释了这些实现速度较慢的部分原因。
Groovy record 在这里默认采用 Java 行为,但如果您愿意,允许您将 getter 用于 hashCode(以及 equals 和 toString)。它会更慢,但现在保留了传统的 JavaBean 风格的 getter 行为。
代码看起来会是这样
@EqualsAndHashCode
record GroovyRecordUpperGetter(String x0, String x1, String x2) {
String x1() { x1.toUpperCase() }
}显式的 @EqualsAndHashCode 注解告诉编译器提供 Groovy 默认生成的 hashCode 字节码,该字节码使用 getter,而不是不使用 getter 的特殊 record 字节码。它最终是相同的哈希算法,但使用 getter 访问组件。
现在我们的测试通过了(使用 assertEquals 而不是 assertNotEquals)
private static final GroovyRecordUpperGetter GROOVY_UPPER_GETTER_1
= new GroovyRecordUpperGetter("a", "b", "c");
private static final GroovyRecordUpperGetter GROOVY_UPPER_GETTER_2
= new GroovyRecordUpperGetter("a", "B", "c");
...
assertEquals(GROOVY_UPPER_GETTER_1.hashCode(), GROOVY_UPPER_GETTER_2.hashCode());总结
Groovy record 具有良好的 hashCode 性能。有时您可能需要启用缓存。在极少数情况下,您可能还需要考虑更换哈希算法或启用 getter,但如果您需要,Groovy 也能轻松实现。
equals 的性能
对于此基准测试,调用了静态实例的 equals 方法,并传入了第二个静态实例。
这是我们的基准测试代码示例
@Benchmark
public void equalsGroovyRecord(Blackhole bh) {
bh.consume(GROOVY_RECORD_LABEL.equals(GROOVY_RECORD_LABEL_2));
}结果
和以前一样,测试是使用 GitHub actions 在各种平台上运行的。结果显示平均耗时(纳秒),因此 Score 越小表示越快。
使用 ubuntu-latest
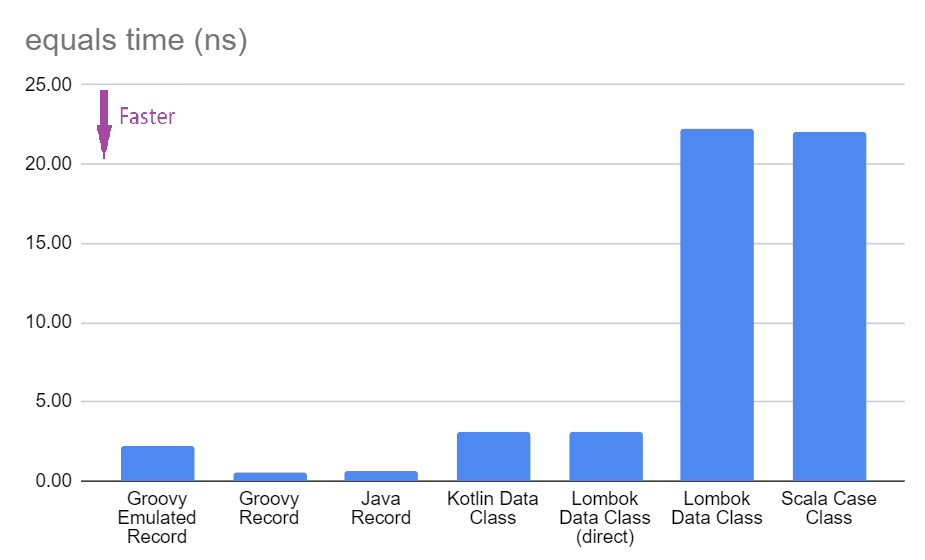
Benchmark Mode Cnt Score Error Units EqualsBenchmark.equalsGroovyEmulatedRecord avgt 10 2.615 ± 0.005 ns/op EqualsBenchmark.equalsGroovyRecord avgt 10 0.603 ± 0.001 ns/op EqualsBenchmark.equalsJavaRecord avgt 10 0.686 ± 0.154 ns/op EqualsBenchmark.equalsKotlinDataLabel avgt 10 3.617 ± 0.002 ns/op EqualsBenchmark.equalsLombokDirectDataLabel avgt 10 3.617 ± 0.002 ns/op EqualsBenchmark.equalsLombokDataLabel avgt 10 24.115 ± 0.014 ns/op EqualsBenchmark.equalsScalaCaseLabel avgt 10 24.130 ± 0.045 ns/op
使用 windows-latest
Benchmark Mode Cnt Score Error Units EqualsBenchmark.equalsGroovyEmulatedRecord avgt 10 2.216 ± 0.004 ns/op EqualsBenchmark.equalsGroovyRecord avgt 10 0.511 ± 0.002 ns/op EqualsBenchmark.equalsJavaRecord avgt 10 0.511 ± 0.001 ns/op EqualsBenchmark.equalsKotlinDataLabel avgt 10 3.066 ± 0.004 ns/op EqualsBenchmark.equalsLombokDirectDataLabel avgt 10 3.068 ± 0.005 ns/op EqualsBenchmark.equalsLombokDataLabel avgt 10 21.451 ± 0.021 ns/op EqualsBenchmark.equalsScalaCaseLabel avgt 10 21.442 ± 0.024 ns/op
使用 macos-latest
Benchmark Mode Cnt Score Error Units EqualsBenchmark.equalsGroovyEmulatedRecord avgt 10 1.943 ± 0.116 ns/op EqualsBenchmark.equalsGroovyRecord avgt 10 0.612 ± 0.013 ns/op EqualsBenchmark.equalsJavaRecord avgt 10 0.579 ± 0.021 ns/op EqualsBenchmark.equalsKotlinDataLabel avgt 10 2.727 ± 0.068 ns/op EqualsBenchmark.equalsLombokDirectDataLabel avgt 10 2.734 ± 0.096 ns/op EqualsBenchmark.equalsLombokDataLabel avgt 10 21.206 ± 2.789 ns/op EqualsBenchmark.equalsScalaCaseLabel avgt 10 20.673 ± 0.766 ns/op
结果图表
和以前一样,我们将对三个平台的结果取平均值
讨论
我们发现对于 hashCode,使用 getter 保留了 JavaBean 类的预期,但调用该方法会产生额外的成本。这种影响对于 equals 来说是双倍的,因为我们调用了 this 和我们正在比较的实例的 getter。这解释了 LombokDataLabel 和 ScalaCaseLabel 实现速度慢的很大一部分原因。
就像我们对 hashCode 讨论的那样,您通常不会修改 record 和类似 record 的类的 getter。但对于允许您这样做的 Java 和 Groovy 来说,这可能会让人感到惊讶。Groovy 默认遵循 Java 行为,但如果您愿意,允许您通过 getter 启用访问。
JLS 在 8.10.3 节中有一个 SmallPoint record 的示例,该示例被讨论为“不良风格”,因为对于 Java record,最后一条语句打印 false。如果我们启用 getter,最后一条语句现在打印 true,如该示例的 Groovy 等效所示
@EqualsAndHashCode
record SmallPoint(int x, int y) {
int x() { this.x < 100 ? this.x : 100 }
int y() { this.y < 100 ? this.y : 100 }
static main(args) {
var p1 = new SmallPoint(200, 300)
var p2 = new SmallPoint(200, 300)
println p1 == p2 // prints true
var p3 = new SmallPoint(p1.x(), p1.y())
println p1 == p3 // prints true
}
}尽管如此,对于这个特定示例,保留正常的字段访问并提供类似紧凑规范构造函数以在构造过程中截断点可能是一种更好的风格。
结论
我们研究了 Groovy record 性能的几个方面,并将其与其他语言进行了比较。Groovy 的默认行为直接依赖于 Java 的行为,但 Groovy 有许多声明式选项可以在需要时调整生成的代码。