
将 Groovy™ 与 Apache Wayang 和 Apache Spark™ 结合使用

发布时间:2022-06-19 01:01PM(最后更新时间:2025-02-20 02:10PM)
为了找到完美的单一麦芽苏格兰威士忌,让我们利用 Apache Wayang 的跨平台数据处理和跨平台机器学习功能,根据风味特征对相关的威士忌进行聚类。
 Apache Wayang(孵化中)是一个用于大数据跨平台处理的 API。它提供了对其他平台(如 Apache Spark 和 Apache Flink)的抽象,以及一个默认的内置流式“平台”。目标是提供一致的开发者体验,无论最终需要轻量级还是高度可伸缩的平台。应用程序的执行在逻辑计划中指定,该计划也是平台无关的。Wayang 会将逻辑计划转换为一组物理操作符,由特定的底层处理平台执行。
Apache Wayang(孵化中)是一个用于大数据跨平台处理的 API。它提供了对其他平台(如 Apache Spark 和 Apache Flink)的抽象,以及一个默认的内置流式“平台”。目标是提供一致的开发者体验,无论最终需要轻量级还是高度可伸缩的平台。应用程序的执行在逻辑计划中指定,该计划也是平台无关的。Wayang 会将逻辑计划转换为一组物理操作符,由特定的底层处理平台执行。
威士忌聚类
![]() 我们将探讨如何将 Apache Wayang 与 Groovy 结合使用,以帮助我们寻找完美的单一麦芽苏格兰威士忌。来自 86 家酿酒厂的威士忌已由专家品酒师根据 12 项标准(酒体、甜度、麦芽味、烟熏味、果味等)进行排名。我们将使用 KMeans 算法计算质心。这类似于 Wayang 文档中的 KMeans 示例,但我们有 12 个维度对应我们的标准,而不是 2 个维度(x 和 y 坐标)。重点是,它说明了涉及迭代的典型数据科学和机器学习算法(典型的 map、filter、reduce 处理风格)。
我们将探讨如何将 Apache Wayang 与 Groovy 结合使用,以帮助我们寻找完美的单一麦芽苏格兰威士忌。来自 86 家酿酒厂的威士忌已由专家品酒师根据 12 项标准(酒体、甜度、麦芽味、烟熏味、果味等)进行排名。我们将使用 KMeans 算法计算质心。这类似于 Wayang 文档中的 KMeans 示例,但我们有 12 个维度对应我们的标准,而不是 2 个维度(x 和 y 坐标)。重点是,它说明了涉及迭代的典型数据科学和机器学习算法(典型的 map、filter、reduce 处理风格)。

KMeans 是一种标准的数据科学聚类技术。在我们的案例中,它将具有相似特征(根据 12 个标准)的威士忌分组到簇中。如果我们有最喜欢的威士忌,很有可能通过查看同一簇中的其他实例来找到类似的产品。如果我们想换个口味,可以在其他簇中寻找威士忌。质心是簇中间的概念“点”。对我们来说,它反映了该簇中威士忌的每个标准的典型衡量值。
实现分布式 KMeans
我们将首先使用 Wayang 的数据处理功能来编写我们自己的分布式 KMeans 算法。我们将回头查看 Wayang 的 ML4all 模块中新的内置 KMeans。
要构建分布式 KMeans 算法,我们需要在最终用于运行应用程序的任何数据处理平台(例如 Apache Spark)上的处理节点之间传递一些信息。因此,我们首先定义这些数据结构。
我们将从定义一个 Point 记录开始
record Point(double[] pts) implements Serializable { }我们已将其设为 Serializable(稍后详细介绍)。它对我们来说不是 2D 或 3D 点,而是对应 12 个标准的 12D。我们只使用一个 double 数组,因此任何维度都将受支持,但 12 来自数据文件中的列数。
我们将定义一个相关的 PointGrouping 记录。它类似于 Point,但会跟踪一个 int 簇 ID 和一个 long 计数,用于在聚类点时使用。
record PointGrouping(double[] pts, int cluster, long count) implements Serializable {
PointGrouping(List<Double> pts, int cluster, long count) {
this(pts as double[], cluster, count)
}
PointGrouping plus(PointGrouping that) {
var newPts = pts.indices.collect{ pts[it] + that.pts[it] }
new PointGrouping(newPts, cluster, count + that.count)
}
PointGrouping average() {
new PointGrouping(pts.collect{ double d -> d/count }, cluster, 1)
}
}我们有 plus 和 average 方法,这在算法的 map/reduce 部分稍后会有所帮助。
KMeans 算法的另一个方面是将点分配到与其最近的质心关联的簇。对于 2 个维度,回想勾股定理,这将是 x 平方加 y 平方的平方根,其中 x 和 y 分别是点与质心在 x 和 y 维度上的距离。我们将在所有维度上执行相同的操作,并定义以下辅助类来捕获算法的这一部分
class SelectNearestCentroid implements ExtendedSerializableFunction<Point, PointGrouping> {
Iterable<PointGrouping> centroids
void open(ExecutionContext context) {
centroids = context.getBroadcast('centroids')
}
PointGrouping apply(Point p) {
var minDistance = Double.POSITIVE_INFINITY
var nearestCentroidId = -1
for (c in centroids) {
var distance = sqrt(p.pts.indices
.collect{ p.pts[it] - c.pts[it] }
.sum{ it ** 2 } as double)
if (distance < minDistance) {
minDistance = distance
nearestCentroidId = c.cluster
}
}
new PointGrouping(p.pts, nearestCentroidId, 1)
}
}在 Wayang 的术语中,SelectNearestCentroid 类是一个 UDF,即用户定义函数。它代表了一部分功能,可以在其中对操作的运行位置做出优化决策。
为了使我们的管道定义更短,我们将在 PipelineOps 辅助类中定义一些有用的操作符
class PipelineOps {
public static SerializableFunction<PointGrouping, Integer> cluster = tpc -> tpc.cluster
public static SerializableFunction<PointGrouping, PointGrouping> average = tpc -> tpc.average()
public static SerializableBinaryOperator<PointGrouping> plus = (tpc1, tpc2) -> tpc1 + tpc2
}现在我们准备好进行 KMeans 脚本了
int k = 5
int iterations = 10
// read in data from our file
var url = WhiskeyWayang.classLoader.getResource('whiskey.csv').file
def rows = new File(url).readLines()[1..-1]*.split(',')
var distilleries = rows*.getAt(1)
var pointsData = rows.collect{ new Point(it[2..-1] as double[]) }
var dims = pointsData[0].pts.size()
// create some random points as initial centroids
var r = new Random()
var randomPoint = { (0..<dims).collect { r.nextGaussian() + 2 } as double[] }
var initPts = (1..k).collect(randomPoint)
var context = new WayangContext()
.withPlugin(Java.basicPlugin())
.withPlugin(Spark.basicPlugin())
var planBuilder = new JavaPlanBuilder(context, "KMeans ($url, k=$k, iterations=$iterations)")
var points = planBuilder
.loadCollection(pointsData).withName('Load points')
var initialCentroids = planBuilder
.loadCollection((0..<k).collect{ idx -> new PointGrouping(initPts[idx], idx, 0) })
.withName('Load random centroids')
var finalCentroids = initialCentroids.repeat(iterations, currentCentroids ->
points.map(new SelectNearestCentroid())
.withBroadcast(currentCentroids, 'centroids').withName('Find nearest centroid')
.reduceByKey(cluster, plus).withName('Aggregate points')
.map(average).withName('Average points')
.withOutputClass(PointGrouping)
).withName('Loop').collect()
println 'Centroids:'
finalCentroids.each { c ->
println "Cluster $c.cluster: ${c.pts.collect('%.2f'::formatted).join(', ')}"
}这里,`k` 是所需簇的数量,`iterations` 是 KMeans 循环的迭代次数。`pointsData` 变量是一个从数据文件加载的 `Point` 实例列表。如果我们的数据集很大,我们会使用 `readTextFile` 方法而不是 `loadCollection`。`initPts` 变量是我们初始质心的一些随机起始位置。由于是随机的,并且考虑到 KMeans 算法的工作方式,我们的一些簇可能没有分配到任何点。我们的算法的工作方式是,在每次迭代中,将所有点分配到它们当前最近的质心,然后根据这些分配计算新的质心。最后,我们输出结果。
另外,我们可能想打印出分配给每个簇的酿酒厂。代码如下
var allocator = new SelectNearestCentroid(centroids: finalCentroids)
var allocations = pointsData.withIndex()
.collect{ pt, idx -> [allocator.apply(pt).cluster, distilleries[idx]] }
.groupBy{ cluster, ds -> "Cluster $cluster" }
.collectValues{ v -> v.collect{ it[1] } }
.sort{ it.key }
allocations.each{ c, ds -> println "$c (${ds.size()} members): ${ds.join(', ')}" }在 Java 流支持的平台上运行
正如我们之前提到的,Wayang 选择哪个平台将运行我们的应用程序。它具有许多功能,可以通过成本函数和负载估算器来影响和优化应用程序的运行方式。对于我们简单的示例,只需知道尽管我们指定了 Java 或 Spark 作为选项,Wayang 知道对于我们的小数据集,Java 流选项是最佳选择。
由于我们使用随机数据初始化算法,我们预计每次运行脚本时结果会略有不同,但这是一次输出
> Task :WhiskeyWayang:run
Centroids:
Cluster0: 2.55, 2.42, 1.61, 0.19, 0.10, 1.87, 1.74, 1.77, 1.68, 1.93, 1.81, 1.61
Cluster2: 1.46, 2.68, 1.18, 0.32, 0.07, 0.79, 1.43, 0.43, 0.96, 1.64, 1.93, 2.18
Cluster3: 3.25, 1.50, 3.25, 3.00, 0.50, 0.25, 1.62, 0.37, 1.37, 1.37, 1.25, 0.25
Cluster4: 1.68, 1.84, 1.21, 0.42, 0.05, 1.32, 0.63, 0.74, 1.89, 2.00, 1.84, 1.74
...如果绘制出来,看起来是这样的
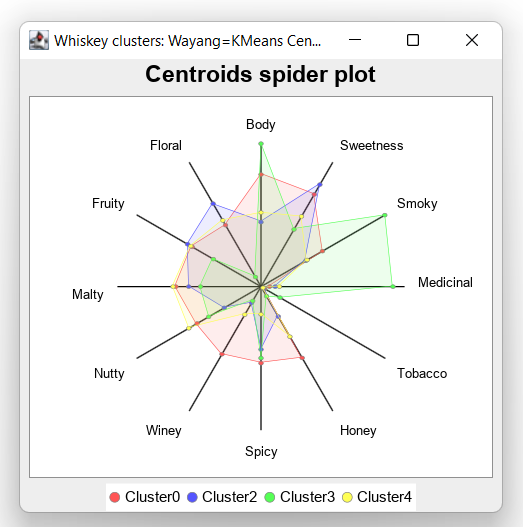
如果您有兴趣,请查看本文末尾存储库链接中的示例,以查看生成此质心蜘蛛图的代码或此项目 GitHub 存储库中的 Jupyter/BeakerX 笔记本。
在 Apache Spark 上运行
 鉴于我们小数据集的大小且没有其他定制,Wayang 将选择基于 Java 流的解决方案。我们可以使用 Wayang 优化功能来影响它选择的处理平台,但为了简单起见,我们只需通过在代码中进行以下更改来禁用配置中的 Java 流平台
鉴于我们小数据集的大小且没有其他定制,Wayang 将选择基于 Java 流的解决方案。我们可以使用 Wayang 优化功能来影响它选择的处理平台,但为了简单起见,我们只需通过在代码中进行以下更改来禁用配置中的 Java 流平台
...
var context = new WayangContext()
// .withPlugin(Java.basicPlugin()) (1)
.withPlugin(Spark.basicPlugin())
...-
已禁用
现在,当我们运行应用程序时,输出将如下所示(与之前类似的解决方案,但增加了 1000 多行 Spark 和 Wayang 日志信息——为演示目的已截断)
[main] INFO org.apache.spark.SparkContext - Running Spark version 3.5.4 [main] INFO org.apache.spark.util.Utils - Successfully started service 'sparkDriver' on port 62081. ... Centroids: Cluster 4: 1.63, 2.26, 1.68, 0.63, 0.16, 1.47, 1.42, 0.89, 1.16, 1.95, 0.89, 1.58 Cluster 0: 2.76, 2.44, 1.44, 0.04, 0.00, 1.88, 1.68, 1.92, 1.92, 2.04, 2.16, 1.72 Cluster 1: 3.11, 1.44, 3.11, 2.89, 0.56, 0.22, 1.56, 0.44, 1.44, 1.44, 1.33, 0.44 Cluster 2: 1.52, 2.42, 1.09, 0.24, 0.06, 0.91, 1.09, 0.45, 1.30, 1.64, 2.18, 2.09 ... [shutdown-hook-0] INFO org.apache.spark.SparkContext - Successfully stopped SparkContext [shutdown-hook-0] INFO org.apache.spark.util.ShutdownHookManager - Shutdown hook called
使用 ML4all
在 Wayang 的最新版本中,引入了一个名为 ML4all 的新抽象。它将用户从机器学习算法选择和低级实现细节的负担中解放出来。许多读者会熟悉支持 MapReduce 的系统如何将功能分为 `map`、`filter` 或 `shuffle` 和 `reduce` 步骤。ML4all 将机器学习算法功能抽象为 7 个操作符:`Transform`、`Stage`、`Compute`、`Update`、`Sample`、`Converge` 和 `Loop`。
Wayang 捆绑了许多这些操作符的实现,但您可以像我们这里为 Transform 操作符编写自己的实现一样
class TransformCSV extends Transform<double[], String> {
double[] transform(String input) {
input.split(',')[2..-1] as double[]
}
}ML4all 包含一个预定义的 `KMeansStageWithZeros` localStage 操作符,但我们将使用自定义操作符以随机质心初始化我们的 KMeans。
class KMeansStageWithRandoms extends LocalStage {
int k, dimension
private r = new Random()
void staging(ML4allModel model) {
double[][] centers = new double[k][]
for (i in 0..<k) {
centers[i] = (0..<dimension).collect { r.nextGaussian() + 2 } as double[]
}
model.put('centers', centers)
}
}定义了这些操作符后,我们现在可以编写脚本了
var dims = 12
var context = new WayangContext()
.withPlugin(Spark.basicPlugin())
.withPlugin(Java.basicPlugin())
var plan = new ML4allPlan(
transformOp: new TransformCSV(),
localStage: new KMeansStageWithRandoms(k: k, dimension: dims),
computeOp: new KMeansCompute(),
updateOp: new KMeansUpdate(),
loopOp: new KMeansConvergeOrMaxIterationsLoop(accuracy, maxIterations)
)
var model = plan.execute('file:' + url, context)
model.getByKey("centers").eachWithIndex { center, idx ->
var pts = center.collect('%.2f'::formatted).join(', ')
println "Cluster$idx: $pts"
}运行时我们得到此输出
Cluster0: 1.57, 2.32, 1.32, 0.45, 0.09, 1.08, 1.19, 0.60, 1.26, 1.74, 1.72, 1.85 Cluster1: 3.43, 1.57, 3.43, 3.14, 0.57, 0.14, 1.71, 0.43, 1.29, 1.43, 1.29, 0.14 Cluster2: 2.73, 2.42, 1.46, 0.04, 0.04, 1.88, 1.69, 1.88, 1.92, 2.04, 2.12, 1.81
讨论
Apache Wayang 的一个目标是允许开发人员编写平台无关的应用程序。尽管这在大多数情况下是正确的,但抽象并不完美。例如,如果我知道我只使用流支持的平台,我不需要担心将任何类序列化(这是 Spark 的要求)。在我们的示例中,我们可以省略 `PointGrouping` 记录的 `implements Serializable` 部分,并且我们的几个管道操作符可能会简化为简单的闭包。这并不是对 Wayang 的批评,毕竟如果您想编写跨平台 UDF,您可能会期望遵循一些规则。相反,它只是为了表明抽象的边缘通常会有泄漏。有时这些泄漏可以被有益地利用,有时它们是等待不知情开发人员的陷阱。
我们使用 JDK17 运行此示例,但在较早的 JDK 版本上,Groovy 将使用模拟记录而不是本机记录,而无需更改源代码。
结论
我们研究了如何使用 Apache Wayang 实现 KMeans 算法,该算法既可以由 JDK 流功能支持,也可以由 Apache Spark 支持。Wayang API 向我们隐藏了编写在分布式平台上工作的代码的一些复杂性以及处理 Spark 平台的一些复杂性。这些抽象并不完美,但它们肯定不难使用,并且在我们希望在平台之间移动时提供了额外的保护。额外的好处是,它们开启了无数的优化可能性。
Apache Wayang 是 Apache 的孵化项目,在毕业之前还有很多工作要做,但之前已经做了大量工作(它以前被称为 Rheem,始于 2015 年)。平台无关的应用程序是一个多年来一直渴望但难以实现的圣杯。看到 Apache Wayang 在实现这一目标方面能取得多大进展,应该会令人兴奋。
更多信息
-
包含源代码的仓库:WhiskeyWayang
-
包含使用各种非分布式库(包括 Apache Commons CSV、Weka、Smile、Tribuo 等)解决此问题的仓库:Whiskey
-
使用 Apache Spark 直接但使用来自
spark-mllib库的内置并行 KMeans 的类似示例:WhiskeySpark -
使用 Apache Ignite 并使用来自
ignite-ml库的内置集群 KMeans 的类似示例:WhiskeyIgnite -
使用 Apache Flink 并使用来自 Flink ML(
flink-ml-uber)库的 KMeans 的类似示例:WhiskeyFlink