
威士忌风味特征再探
发布日期:2025-05-02 11:30 AM
|
让我们初探 Underdog 和 Matrix,这两个新的由 Groovy 驱动的数据帧库。我们将探索威士忌的风味特征! |
在之前的博客文章中,我们研究了使用以下方法对威士忌特征进行聚类:
-
Apache Wayang 的跨平台机器学习 支持原生和 Apache Spark™ 数据处理平台
此外,groovy-data-science 仓库还包含使用其他技术(包括)进行此案例研究的示例:
-
数据操作:Tablesaw、Datumbox、Apache Commons CSV、Tribuo
-
聚类:Smile、Apache Commons Math、Datumbox、Weka、Encog、Elki、Tribuo
-
可视化:XChart、Tablesaw Plot.ly、Smile visualization、JFreeChart
-
扩展聚类:Apache Ignite、Apache Spark、Apache Wayang、Apache Flink、Apache Beam
案例研究
 在寻找完美的单一麦芽苏格兰威士忌的过程中,86 家酿酒厂生产的威士忌已由专家品尝师根据 12 个标准(酒体、甜度、麦芽味、烟熏味、果味等)进行排名。我们将使用 KMeans 等算法将威士忌聚类为相关组。
在寻找完美的单一麦芽苏格兰威士忌的过程中,86 家酿酒厂生产的威士忌已由专家品尝师根据 12 个标准(酒体、甜度、麦芽味、烟熏味、果味等)进行排名。我们将使用 KMeans 等算法将威士忌聚类为相关组。
初探 Underdog
Underdog 是一个相对较新的数据科学库。让我们用它来探索威士忌特征。它拥有许多由 Groovy 驱动的功能,提供了极具表现力的开发体验。
Underdog 包含以下模块:underdog-dataframe、underdog-graphs、underdog-plots、underdog-ml 和 underdog-ta。我们将使用除了最后一个之外的所有模块。
Underdog 建立在 JVM 生态系统中一些知名的数据科学库之上,如 Smile、Tablesaw 和 Apache ECharts。如果您使用过这些库中的任何一个,您就会认出其中一些功能。
首先,我们将 CSV 文件加载到 Underdog 数据帧中(删除一个我们不需要的列)
def file = getClass().getResource('whisky.csv').file
def df = Underdog.df().read_csv(file).drop('RowID')让我们看看数据的形状和模式
println df.shape()
println df.schema()它给出以下输出
86 rows X 13 cols
Structure of whisky.csv
Index | Column Name | Column Type |
-----------------------------------------
0 | Distillery | STRING |
1 | Body | INTEGER |
2 | Sweetness | INTEGER |
3 | Smoky | INTEGER |
4 | Medicinal | INTEGER |
5 | Tobacco | INTEGER |
6 | Honey | INTEGER |
7 | Spicy | INTEGER |
8 | Winey | INTEGER |
9 | Nutty | INTEGER |
10 | Malty | INTEGER |
11 | Fruity | INTEGER |
12 | Floral | INTEGER |
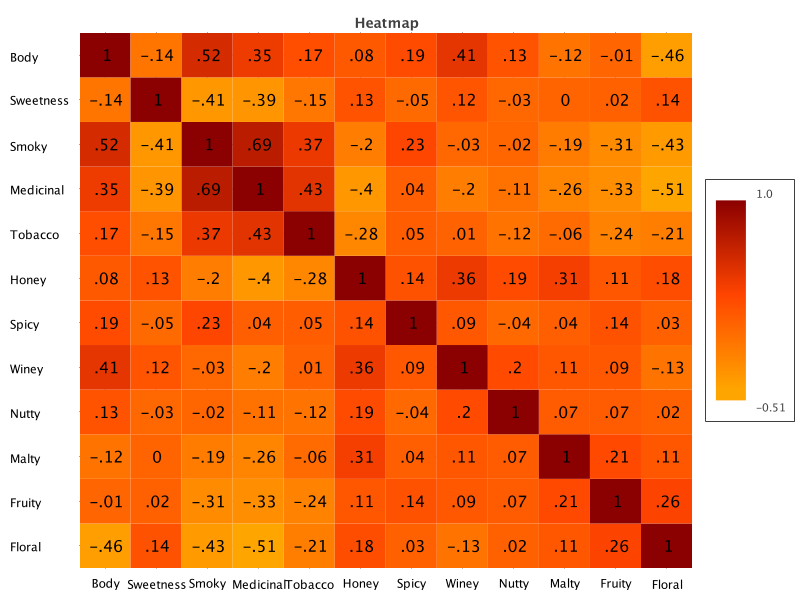
当数据维度很多时,理解列之间的关系可能很困难。我们可以查看相关矩阵来帮助我们理解是否存在冗余数据,例如,甜度和蜂蜜,或者烟草和烟熏味,是同一事物的两种衡量方式,还是不同的事物。
Underdog 有一个内置的绘图功能,所以我们来收集数值特征并绘制相关矩阵
def plot = Underdog.plots()
def features = df.columns - 'Distillery'
plot.correlationMatrix(df[features]).show()其输出如下
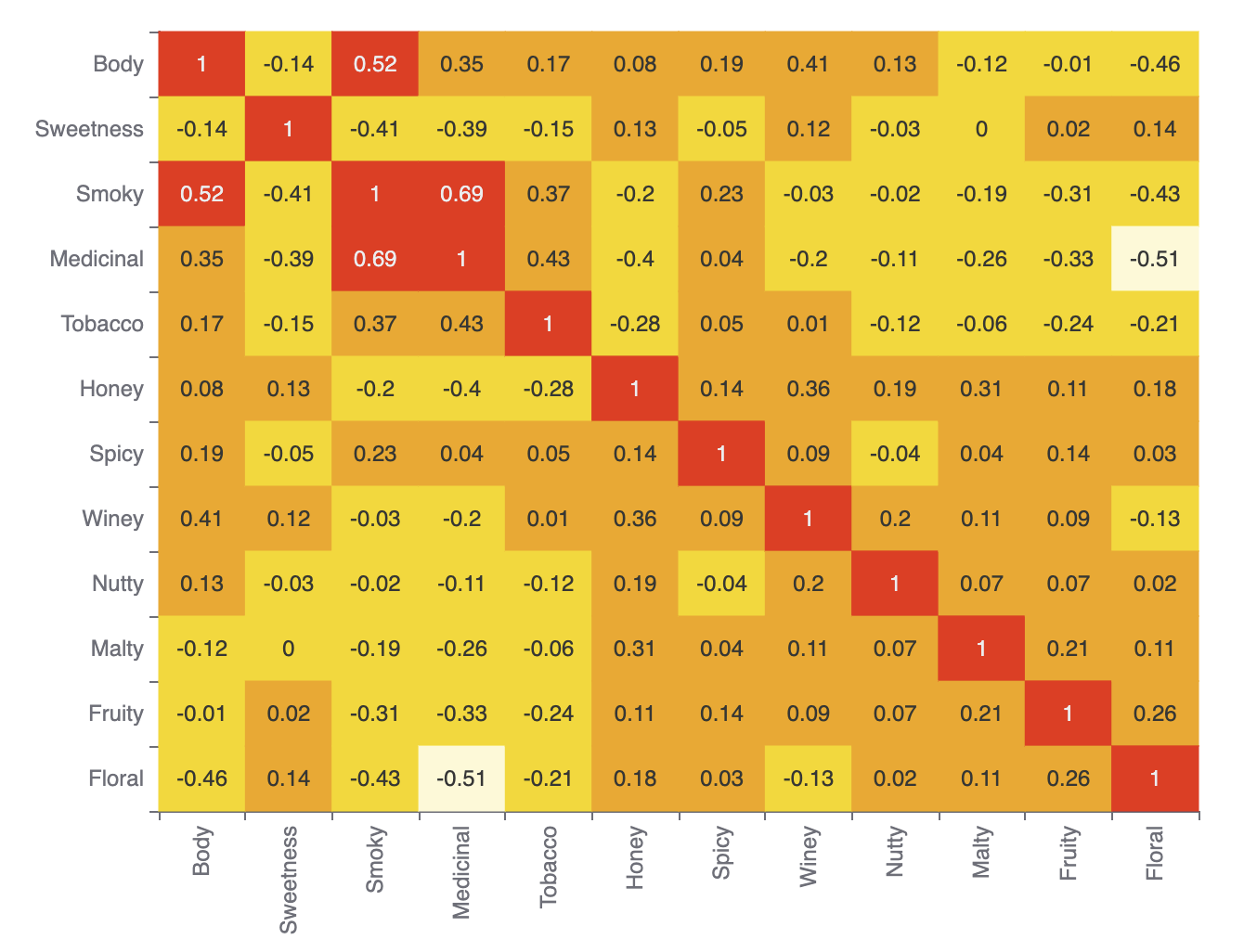
我们可以看到不同的风味指标是相当独特的。最高的相关性存在于烟熏味和药味之间,以及烟熏味和酒体之间。有些,比如花香和药味,则非常不相关。
Groovy 具有灵活的语法。Underdog 利用了这一点,借用了 Groovy 的列表表示法,允许在数据框内进行数据过滤的列表达式。让我们使用列表达式来查找特定风味的威士忌,在本例中是具有一定果味和一定甜味的威士忌。
def selected = df[df['Fruity'] > 2 & df['Sweetness'] > 2]
println selected.shape()我们可以看到有 6 种这样的威士忌
6 rows X 13 cols
让我们用雷达图来看看这些风味特征。`underdog-plots` 模块有快捷方式,可以轻松访问 Apache ECharts 库。其中有一个快捷方式用于单个系列的雷达图。让我们看看我们选择的威士忌的第 0 行。
plot.radar(
features,
[4] * features.size(),
selected[features].toList()[0],
selected['Distillery'][0]
).show()其输出如下
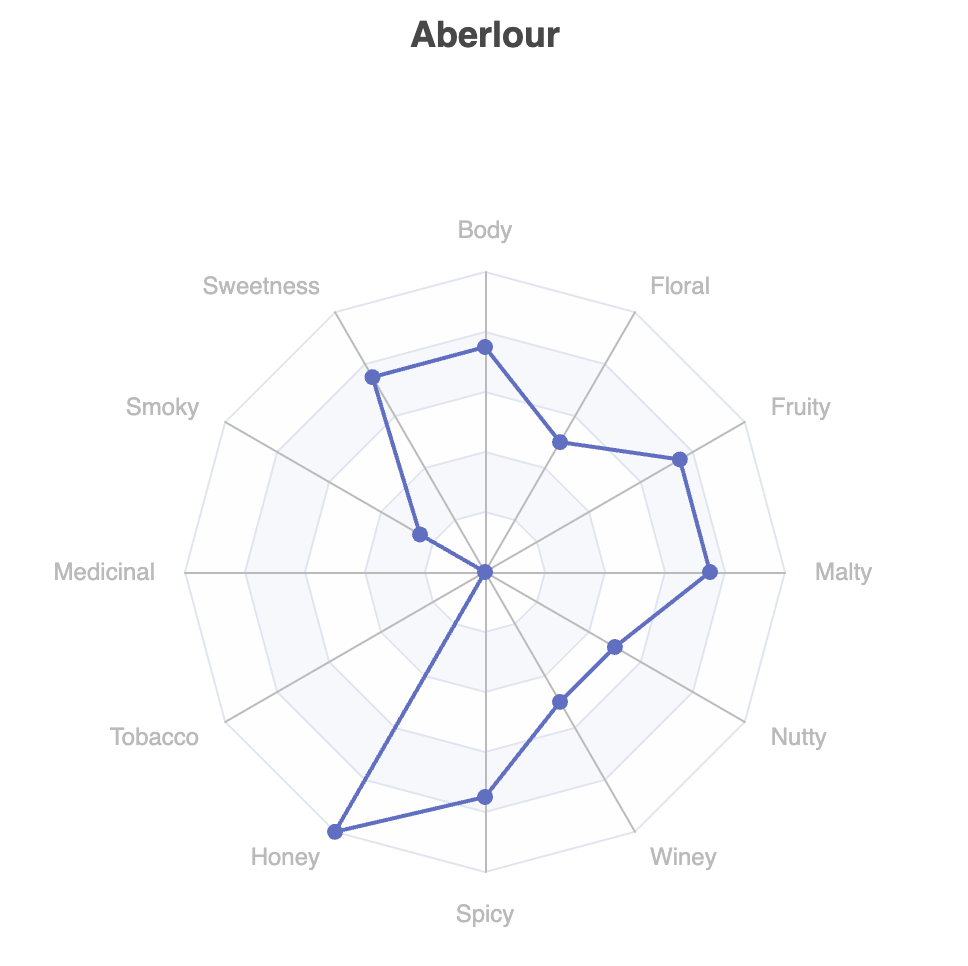
这会弹出在浏览器窗口中显示上述代码,但也提供其他输出选项。
这显示了我们选定的 6 种感兴趣的威士忌中的一种。我们当然可以制作另外 5 个类似的图表。该库(目前)没有预构建的图表,可以同时显示多个系列,但该库以相当灵活的方式构建,我们可以向下深入一层,不费太多力气就能自行构建这样的图表。
def multiRadar = Chart.createGridOptions('Whisky flavor profiles',
'Somewhat sweet, somewhat fruity') +
create {
radar {
radius('50%')
indicator(features.zip([4] * features.size())
.collect { n, mx -> [name: n, max: mx] })
}
selected.toList().each { row ->
series(RadarSeries) {
data([[name: row[0], value: row[1..-1]]])
}
}
}.customize {
legend {
show(true)
}
}
plot.show(multiRadar)其输出如下
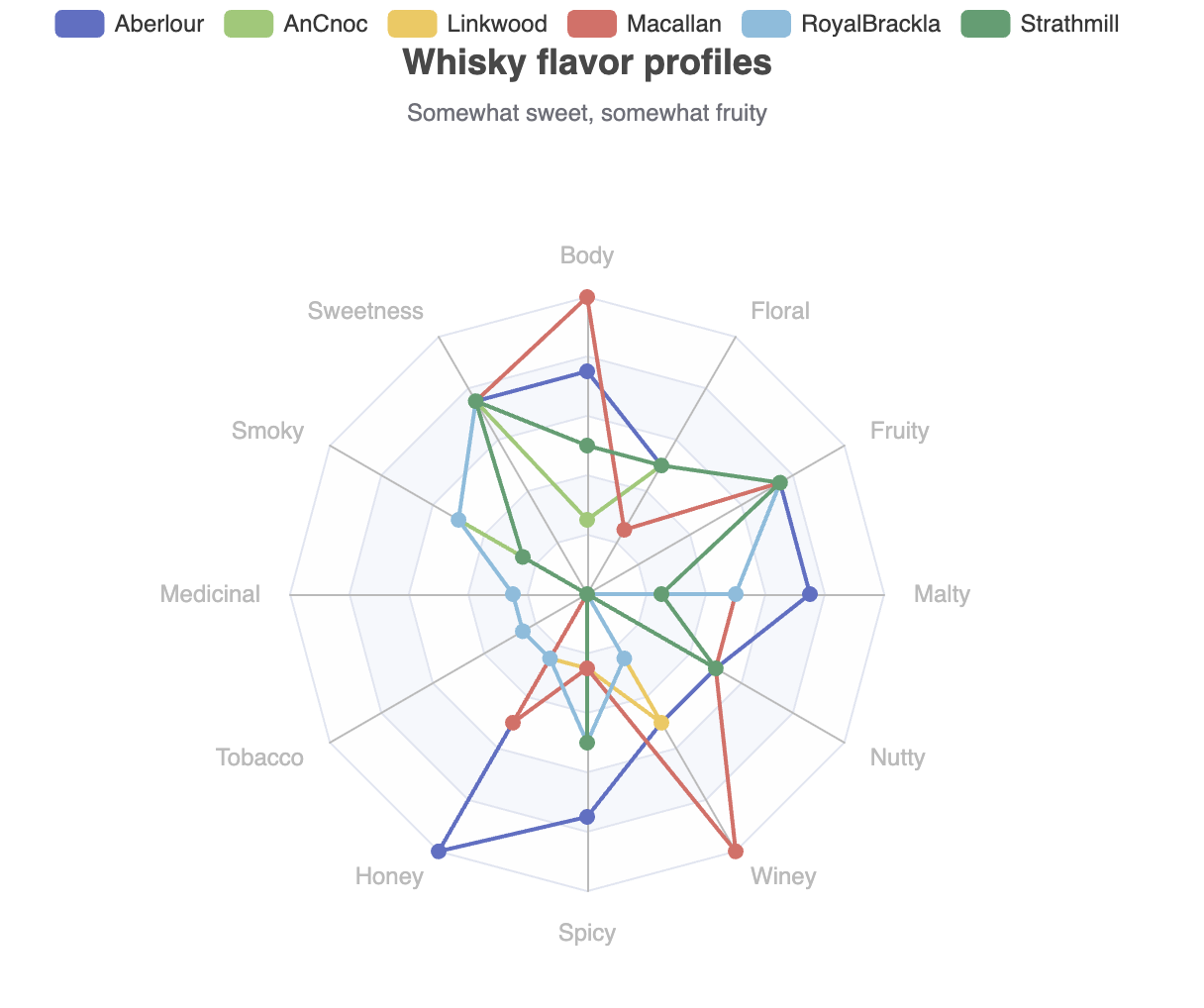
当一个库不提供你需要的功能时,常常会令人恼火,所以我们能够即时添加这样的功能真是太棒了!
现在,我们使用 K-means 对酿酒厂进行聚类,并将聚类分配结果放回数据帧中。
def ml = Underdog.ml()
def data = df[features] as double[][]
def clusters = ml.clustering.kMeans(data, nClusters: 3)
df['Cluster'] = clusters.toList()Underdog 提供了一些聚合函数,因此我们可以检查聚类分配的计数。
println df.agg([Distillery:'count'])
.by('Cluster')
.rename('Whisky Cluster Sizes')其输出如下
Whisky Cluster Sizes
Cluster | Count [Distillery] |
----------------------------------
0 | 25 |
2 | 44 |
1 | 17 |
或者,我们可以轻松打印出每个聚类中的酿酒厂
println 'Clusters'
for (int i in clusters.toSet()) {
println "$i:${df[df['Cluster'] == i]['Distillery'].join(', ')}"
}它给出以下输出
Clusters 0:Aberfeldy, Aberlour, Auchroisk, Balmenach, Belvenie, BenNevis, Benrinnes, Benromach, BlairAthol, Dailuaine, Dalmore, Edradour, GlenOrd, Glendronach, Glendullan, Glenfarclas, Glenlivet, Glenrothes, Glenturret, Knochando, Longmorn, Macallan, Mortlach, RoyalLochnagar, Strathisla 1:Ardbeg, Balblair, Bowmore, Bruichladdich, Caol Ila, Clynelish, GlenGarioch, GlenScotia, Highland Park, Isle of Jura, Lagavulin, Laphroig, Oban, OldPulteney, Springbank, Talisker, Teaninich 2:AnCnoc, Ardmore, ArranIsleOf, Auchentoshan, Aultmore, Benriach, Bladnoch, Bunnahabhain, Cardhu, Craigallechie, Craigganmore, Dalwhinnie, Deanston, Dufftown, GlenDeveronMacduff, GlenElgin, GlenGrant, GlenKeith, GlenMoray, GlenSpey, Glenallachie, Glenfiddich, Glengoyne, Glenkinchie, Glenlossie, Glenmorangie, Inchgower, Linkwood, Loch Lomond, Mannochmore, Miltonduff, OldFettercairn, RoyalBrackla, Scapa, Speyburn, Speyside, Strathmill, Tamdhu, Tamnavulin, Tobermory, Tomatin, Tomintoul, Tomore, Tullibardine
我们可能还对聚类中心感兴趣,即每个聚类的平均风味特征。目前,Underdog 在底层通过 K-Means 使用 Smile 进行聚类。Smile K-Means 模型已经计算出中心点,但目前该信息在 Underdog 简化的 K-Means 抽象后面。
然而,重新计算中心点并不难。
def summary = df
.agg(features.collectEntries{ f -> [f, 'mean']})
.by('Cluster')
.sort_values(false, 'Cluster')
.rename('Flavour Centroids')我们将采用结果并进行一些小的格式更改。
(summary.columns - 'Cluster').each { c ->
summary[c] = summary[c](Double, Double) { it.round(3) }
}
println summary其输出如下
Mean flavor by Cluster
Cluster | Mean [Body] | Mean [Sweetness] | Mean [Smoky] | Mean [Medicinal] | Mean [Tobacco] | Mean [Honey] | Mean [Spicy] | Mean [Winey] | Mean [Nutty] | Mean [Malty] | Mean [Fruity] | Mean [Floral] |
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
0 | 2.76 | 2.44 | 1.44 | 0.04 | 0 | 1.88 | 1.68 | 1.92 | 1.92 | 2.04 | 2.16 | 1.72 |
1 | 2.529 | 1.647 | 2.765 | 2.118 | 0.294 | 0.647 | 1.647 | 0.588 | 1.353 | 1.412 | 1.353 | 0.941 |
2 | 1.5 | 2.455 | 1.114 | 0.227 | 0.114 | 1.114 | 1.114 | 0.591 | 1.25 | 1.818 | 1.773 | 1.977 |
查看质心是尝试理解威士忌如何分组的一种方法。但是,可视化 12 维数据非常困难,所以我们改为使用 PCA 将数据投影到 2 维,并将这些投影存储回数据帧中。
def pca = ml.features.pca(data, 2)
def projected = pca.apply(data)
df['X'] = projected*.getAt(0)
df['Y'] = projected*.getAt(1)我们现在可以按如下方式创建此数据的散点图
plot.scatter(
df['X'],
df['Y'],
df['Cluster'],
'Whisky Clusters (kMeans)'
).show()输出如下
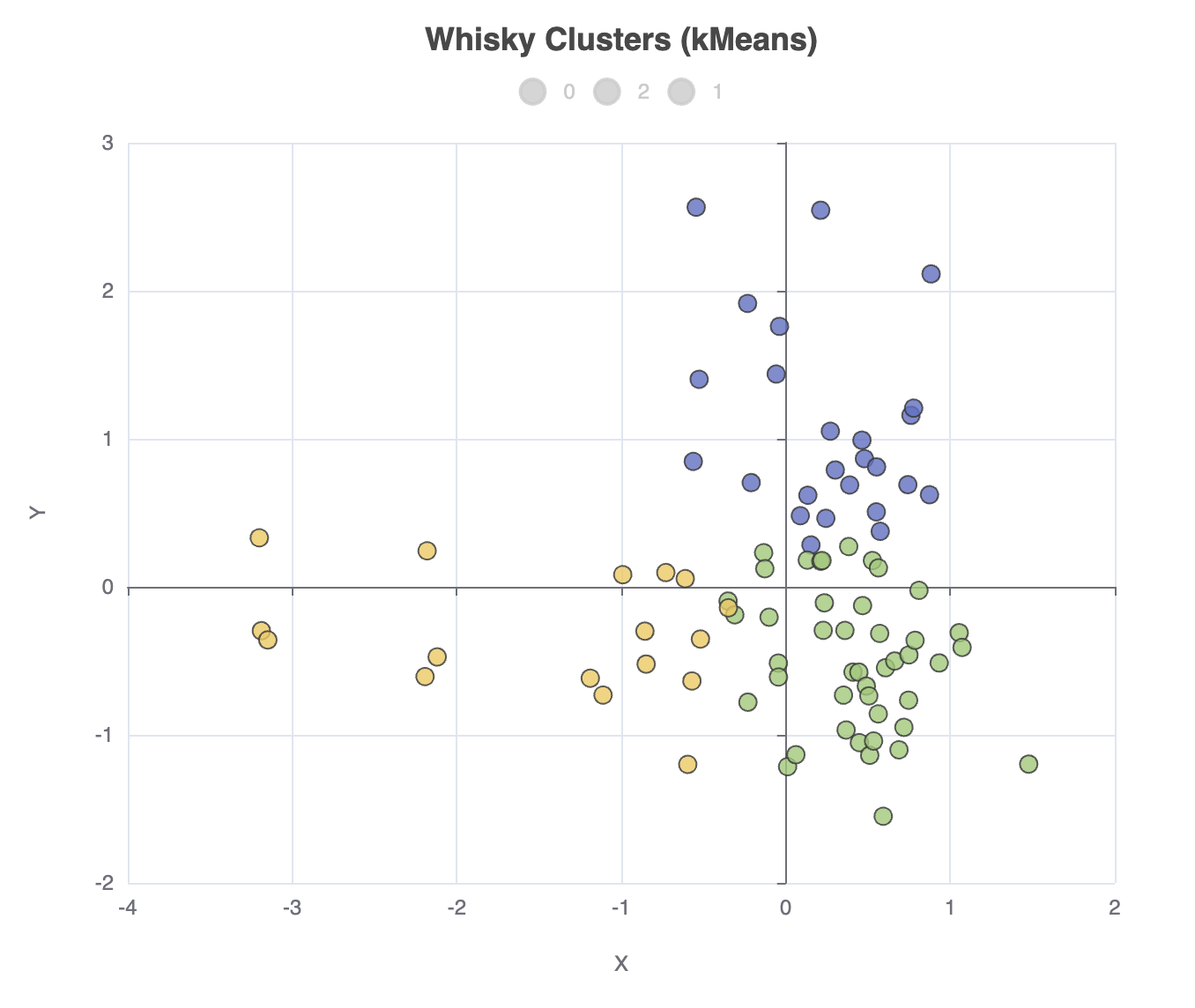
我们可以更改我们的聚类算法,例如 `ml.clustering.agglomerative(data, nClusters: 3)`,在这种情况下,聚类分配计数将如下所示:
Whisky Cluster Sizes
Cluster | Count [Distillery] |
----------------------------------
1 | 39 |
2 | 41 |
0 | 6 |
散点图看起来像这样
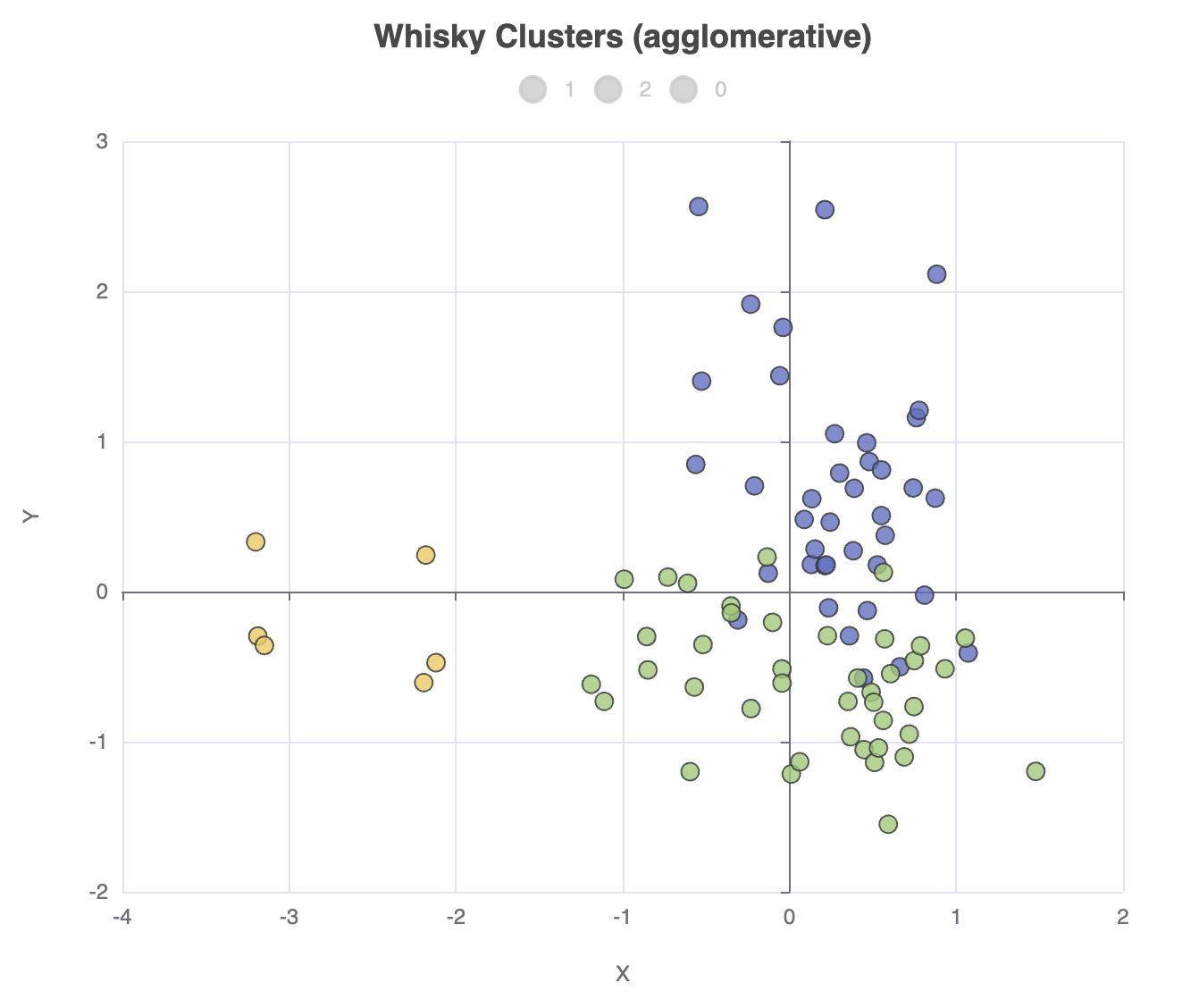
初探 Matrix
Matrix 库使处理表格数据的矩阵变得容易。Matrix 项目包含以下模块:matrix-core、matrix-stats、matrix-datasets、matrix-spreadsheet、matrix-csv、matrix-json、matrix-xcharts、matrix-sql、matrix-parquet、matrix-bigquery、matrix-charts 和 matrix-tablesaw。
Matrix 虽然是新库,但它确实建立在常见的 JVM 数据科学库之上,例如 Tablesaw 和 Apache Commons Math。对于某些功能,如聚类和降维,Matrix 与 Smile 等库配合良好。
对于首次介绍,我们将重点介绍 matrix-core、matrix-stats、matrix-csv 和 matrix-xchart 模块。
让我们读取数据,删除不需要的列,并探索其大小。
def url = getClass().getResource('whisky.csv')
Matrix m = CsvImporter.importCsv(url).dropColumns('RowID')
println m.dimensions()输出如下
[observations:86, variables:13]
目前,数据都是字符串。Matrix 提供了 `convert` 选项,用于将数据转换为正确的类型。它还有各种归一化方法。我们希望数据是数字,我们将使用的一些功能(例如,雷达图)假设我们的数据已归一化(值介于 0 和 1 之间)。
与其使用 `convert` 或归一化方法,这里我们将展示 `apply` 功能,它将在我们的示例中实现相同的结果。
def features = m.columnNames() - 'Distillery'
def size = features.size()
features.each(feature -> m.apply(feature) { it.toDouble() / 4 })现在,像我们使用 Underdog 那样,我们想要执行一个查询来查找并显示风味上有点果味和有点甜味的威士忌。
def selected = m.subset { it.Fruity > 0.5 && it.Sweetness > 0.5 }
println selected.dimensions()
println selected.head(10)其输出如下
[observations:6, variables:13] Distillery Body Sweetness Smoky Medicinal Tobacco Honey Spicy Winey Nutty Malty Fruity Floral Aberlour 0.75 0.75 0.25 0.0 0.0 1.0 0.75 0.5 0.5 0.75 0.75 0.5 AnCnoc 0.25 0.75 0.5 0.0 0.0 0.5 0.0 0.0 0.5 0.5 0.75 0.5 Linkwood 0.5 0.75 0.25 0.0 0.0 0.25 0.25 0.5 0.0 0.25 0.75 0.5 Macallan 1.0 0.75 0.25 0.0 0.0 0.5 0.25 1.0 0.5 0.5 0.75 0.25 RoyalBrackla 0.5 0.75 0.5 0.25 0.25 0.25 0.5 0.25 0.0 0.5 0.75 0.5 Strathmill 0.5 0.75 0.25 0.0 0.0 0.0 0.5 0.0 0.5 0.25 0.75 0.5
我们可以只为第一个绘制雷达图
def transparency = 80
def aberlour = selected.subset(0..0)
def rc = RadarChart.create(aberlour).addSeries('Distillery', transparency)
new SwingWrapper(rc.exportSwing().chart).displayChart()|
注意
|
如果 `matrix-xchart` 不具备您所需的功能,可以考虑查看 `matrix-chart` 库。它们提供了许多类似的图表,但也有一些差异。 |
输出如下
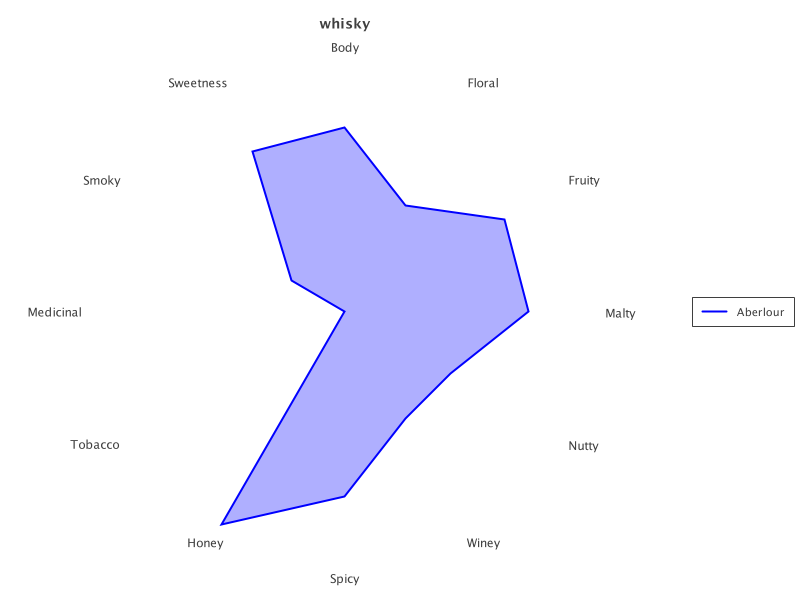
同样的图表也适用于显示所有选定的威士忌
rc = RadarChart.create(selected).addSeries('Distillery', transparency)
new SwingWrapper(rc.exportSwing().chart).displayChart()它看起来像这样
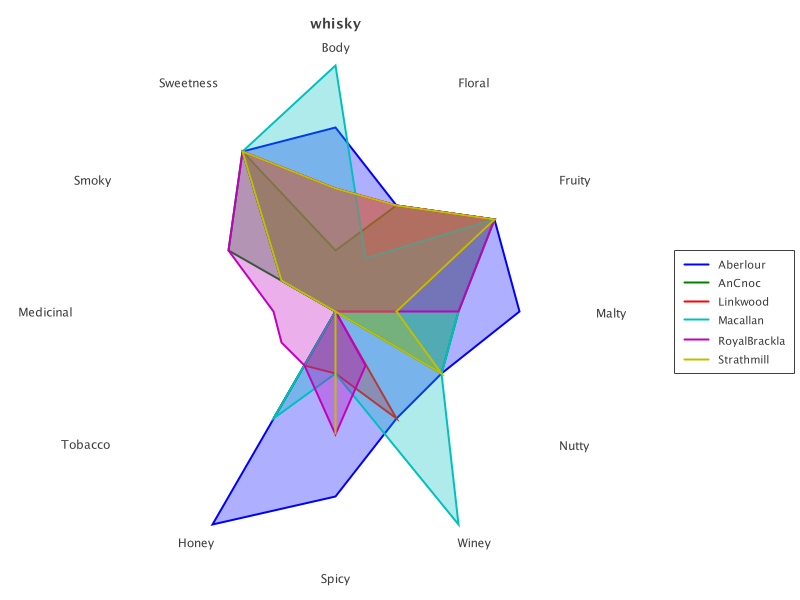
现在让我们对威士忌进行聚类。我们将使用 Smile 的 K-Means 功能。让我们应用 K-Means,并将分配的聚类放回矩阵中。
def iterations = 20
def data = m.selectColumns(*features) as double[][]
def model = KMeans.fit(data, 3, iterations)
m['Cluster'] = model.group().toList()我们可以使用 groovy-ginq 功能检查聚类分配,它与 Matrix 配合得很好。
def result = GQ {
from w in m
groupby w.Cluster
orderby w.Cluster
select w.Cluster, count(w.Cluster) as Count
}
println result其输出如下
+---------+-------+ | Cluster | Count | +---------+-------+ | 0 | 51 | | 1 | 23 | | 2 | 12 | +---------+-------+
我们可以将 ginq 结果转换回矩阵,如下所示:
println Matrix.builder('Cluster allocation').ginqResult(result).build().content()其输出如下
Cluster allocation: 3 obs * 2 variables
Cluster Count
0 51
1 23
2 12
对于检查聚类分配的特定问题,我们也可以使用正常的 Groovy 扩展方法。
assert m.rows().countBy{ it.Cluster } == [0:51, 1:23, 2:12]聚类质心,即每个聚类的平均风味特征。这些可以从 Smile 模型中获取(我们将通过乘以 4 对值进行反归一化,然后将其美化打印到 3 位小数)。
println 'Cluster ' + features.join(' ')
model.centers().eachWithIndex { c, i ->
println " $i: ${c*.multiply(4).collect('%.3f'::formatted).join(' ')}"
}其输出如下
Cluster Body Sweetness Smoky Medicinal Tobacco Honey Spicy Winey Nutty Malty Fruity Floral 0: 1.569 2.392 1.235 0.294 0.098 1.098 1.255 0.608 1.235 1.745 1.784 1.961 1: 2.783 2.435 1.478 0.043 0.000 1.913 1.652 2.000 1.957 2.087 2.174 1.696 2: 2.833 1.583 2.917 2.583 0.417 0.583 1.417 0.583 1.500 1.500 1.167 0.583
我们还可以使用主成分分析(PCA)投影到二维。我们将再次为此使用 Smile 功能。让我们投影到二维并将投影坐标放回矩阵中。
def pca = PCA.fit(data)
def projected = pca.getProjection(2).apply(data)
m['X'] = projected*.getAt(0)
m['Y'] = projected*.getAt(1)现在让我们创建一个散点图,显示根据投影坐标映射的酿酒厂。`ScatterPlot#create` 方法最紧凑的形式假设一个系列,但我们自己添加每个系列并不难。
def clusters = m['Cluster'].toSet()
def sc = ScatterChart.create(m)
sc.title = 'Whisky Flavor Clusters'
for (i in clusters) {
def series = m.subset('Cluster', i)
sc.addSeries("Cluster $i", series.column('X'), series.column('Y'))
}
new SwingWrapper(sc.exportSwing().chart).displayChart()运行时,我们得到以下输出
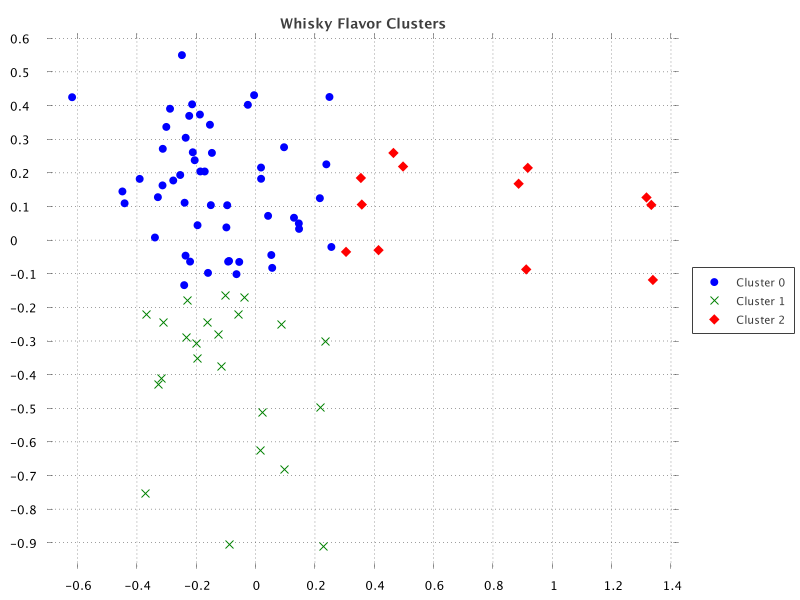
Matrix 开箱即用不提供相关热图,但它有热图和相关功能。我们自己实现一个也很容易。
def corr = [size<..0, 0..<size].combinations().collect { i, j ->
Correlation.cor(data*.getAt(j), data*.getAt(i)).round(2)
}
def corrMatrix = Matrix.builder().data(X: 0..<corr.size(), Heat: corr)
.types([Number] * 2)
.matrixName('Heatmap')
.build()
def hc = HeatmapChart.create(corrMatrix)
.addSeries('Heat Series', features.reverse(), features,
corrMatrix.column('Heat').collate(size))其输出如下
结论
我们已经研究了如何使用 Underdog 和 Matrix 对威士忌风味特征进行分类。