
使用深度学习、Groovy™ 和 GraalVM 对鸢尾花进行分类
发布时间:2022-06-25 10:52AM(最后更新:2022-06-27 11:16AM)

groovy-data-science repo 中的Iris 项目专门针对此示例。它包括许多 Groovy 脚本和一个 Jupyter/BeakerX 笔记本,突出显示了此示例,比较和对比了各种库和各种分类算法。
| 涵盖的技术/库 | |
|---|---|
数据操作 |
|
分类 |
|
可视化 |
|
涵盖的主要方面/算法 |
|
涵盖的其他方面/算法 |
如果您对这些额外的技术感兴趣,请随意浏览这些其他示例和 Jupyter/BeakerX 笔记本。
对于这篇博客,我们只看深度学习的例子。我们将使用 Encog、Eclipse DeepLearning4J 和 Deep Netts(使用标准 Java 和使用 GraalVM 作为原生镜像)来研究解决方案,但首先简要介绍一下。
深度学习
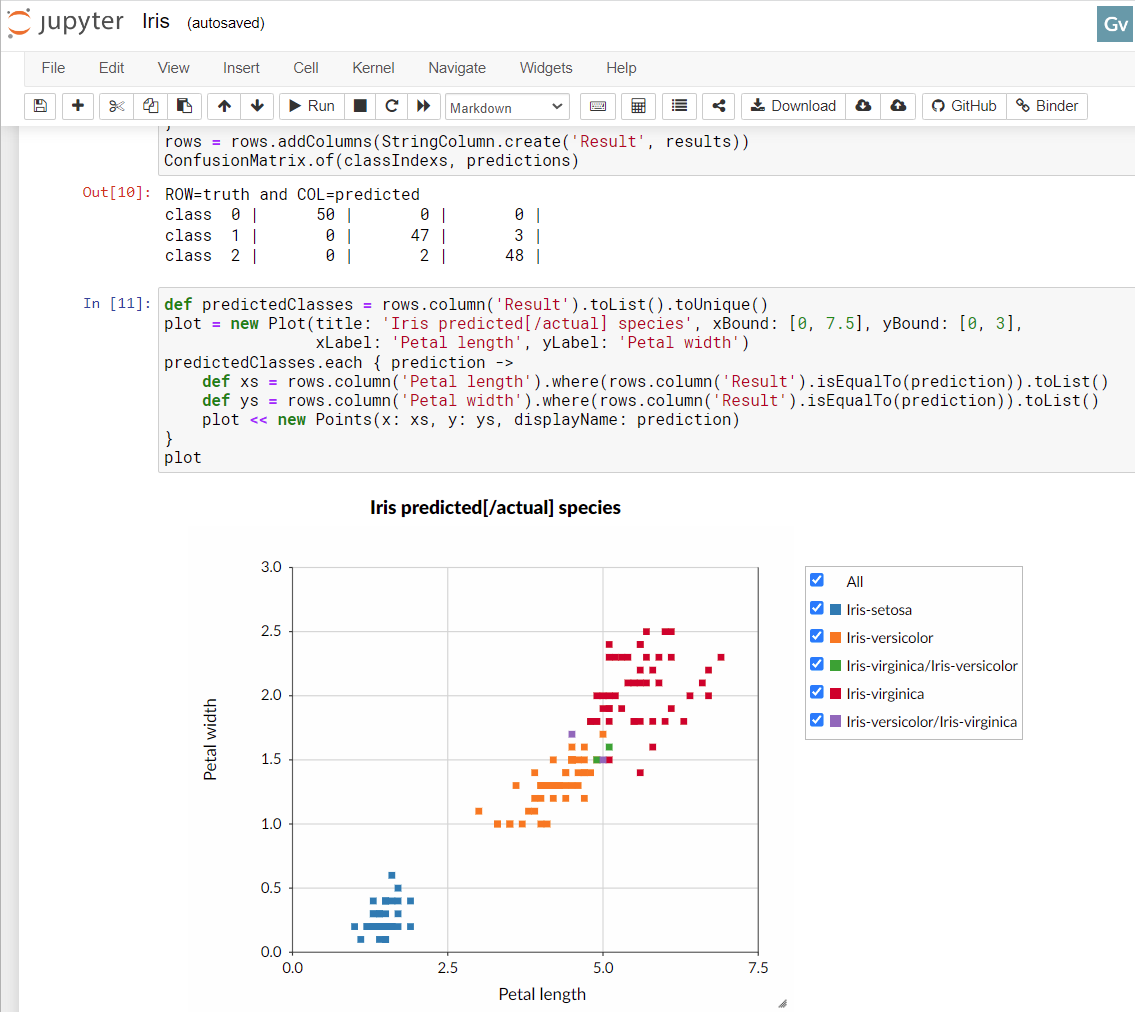
深度学习属于机器学习和人工智能的分支。它涉及人工神经网络的多个层(因此是“深度”)。配置此类网络的方法有很多,细节超出了本博客文章的范围,但我们可以给出一些基本细节。我们将有四个输入节点,对应于我们四个特征的测量值。我们将有三个输出节点,对应于每个可能的
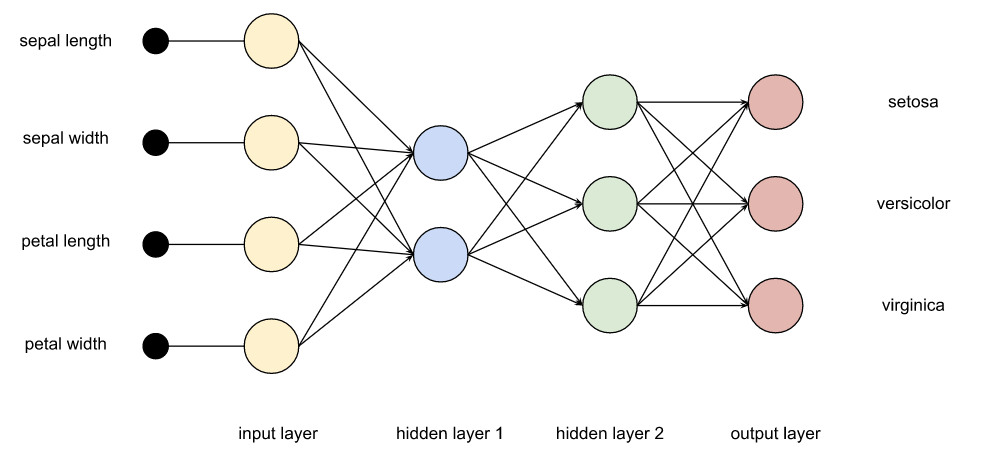
该网络中的每个节点在某种程度上模仿了人脑中的神经元。同样,我们将简化细节。每个节点都有多个输入,这些输入被赋予特定的权重,以及一个激活函数,它将决定我们的节点是否“触发”。训练模型是一个确定最佳权重的过程。
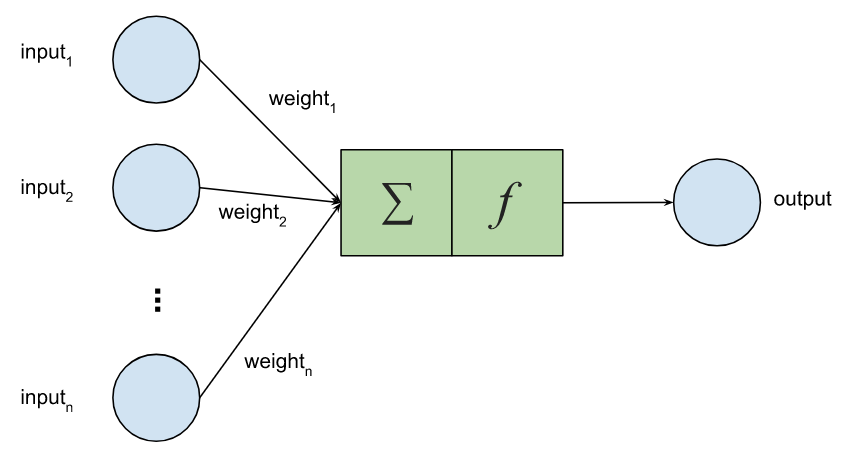
任何节点将输入转换为输出所涉及的数学并不难。我们可以自己编写(如此处所示,使用矩阵和Apache Commons Math进行数字识别示例),但幸运的是我们不必这样做。我们将要使用的库为我们完成了大部分工作。它们通常提供一个流畅的 API,让我们以一种声明式的方式指定网络中的层。
在探索我们的例子之前,我们应该预先警告大家,虽然我们确实对运行例子进行了计时,但没有尝试严格确保不同技术之间的例子是相同的。不同的技术支持略微不同的设置各自网络层的方式。参数经过调整,因此在运行时,验证中通常最多只有一个或两个错误。此外,运行的初始参数可以用随机或预定义的种子设置。当使用随机种子时,每次运行都会有略微不同的错误。如果我们想在技术之间进行更严格的时间比较,我们需要对例子进行一些额外的对齐并使用像 JMH 这样的框架。尽管如此,它应该能大致指导各种技术的速度。
Encog
Encog 是一个纯 Java 机器学习框架,创建于 2008 年。它还有一个针对 .Net 用户的 C# 版本。Encog 是一个简单的框架,支持一些其他地方找不到的高级算法,但不如其他更近期的框架使用广泛。
我们使用 Encog 进行鸢尾花分类的完整源代码在此处这里,但关键部分是
def model = new EncogModel(data).tap {
selectMethod(data, TYPE_FEEDFORWARD)
report = new ConsoleStatusReportable()
data.normalize()
holdBackValidation(0.3, true, 1001) // test with 30%
selectTrainingType(data)
}
def bestMethod = model.crossvalidate(5, true) // 5-fold cross-validation
println "Training error: " + pretty(calculateRegressionError(bestMethod, model.trainingDataset))
println "Validation error: " + pretty(calculateRegressionError(bestMethod, model.validationDataset))当我们运行示例时,我们看到
paulk@pop-os:/extra/projects/iris_encog$ time groovy -cp "build/lib/*" IrisEncog.groovy 1/5 : Fold #1 1/5 : Fold #1/5: Iteration #1, Training Error: 1.43550735, Validation Error: 0.73302237 1/5 : Fold #1/5: Iteration #2, Training Error: 0.78845427, Validation Error: 0.73302237 ... 5/5 : Fold #5/5: Iteration #163, Training Error: 0.00086231, Validation Error: 0.00427126 5/5 : Cross-validated score:0.10345818553910753 Training error: 0.0009 Validation error: 0.0991 Prediction errors: predicted: Iris-virginica, actual: Iris-versicolor, normalized input: -0.0556, -0.4167, 0.3898, 0.2500 Confusion matrix: Iris-setosa Iris-versicolor Iris-virginica Iris-setosa 19 0 0 Iris-versicolor 0 15 1 Iris-virginica 0 0 10 real 0m3.073s user 0m9.973s sys 0m0.367s
我们不会解释所有统计数据,但它基本上说明我们有一个预测错误率很低的相当好的模型。如果你看到这篇博客前面笔记本图像中的绿色和紫色点,你会发现有些点很难一直正确预测。混淆矩阵显示模型在验证数据集上错误地预测了一朵花。
这个库一个非常好的地方是它是一个单一的 jar 依赖!
Eclipse DeepLearning4j
Eclipse DeepLearning4j 是一套用于在 JVM 上运行深度学习的工具。它支持扩展到 Apache Spark,并且在多个级别上与 Python 集成。它还提供了与 GPU 和 C/++ 库的集成,用于原生集成。
我们使用 DeepLearning4J 进行鸢尾花分类的完整源代码在此处这里,主要部分如下所示
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
.activation(Activation.TANH) // global activation
.weightInit(WeightInit.XAVIER)
.updater(new Sgd(0.1))
.l2(1e-4)
.list()
.layer(new DenseLayer.Builder().nIn(numInputs).nOut(3).build())
.layer(new DenseLayer.Builder().nIn(3).nOut(3).build())
.layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX) // override activation with softmax for this layer
.nIn(3).nOut(numOutputs).build())
.build()
def model = new MultiLayerNetwork(conf)
model.init()
model.listeners = new ScoreIterationListener(100)
1000.times { model.fit(train) }
def eval = new Evaluation(3)
def output = model.output(test.features)
eval.eval(test.labels, output)
println eval.stats()当我们运行这个示例时,我们看到
paulk@pop-os:/extra/projects/iris_encog$ time groovy -cp "build/lib/*" IrisDl4j.groovy [main] INFO org.nd4j.linalg.factory.Nd4jBackend - Loaded [CpuBackend] backend [main] INFO org.nd4j.nativeblas.NativeOpsHolder - Number of threads used for linear algebra: 4 [main] INFO org.nd4j.nativeblas.Nd4jBlas - Number of threads used for OpenMP BLAS: 4 [main] INFO org.nd4j.linalg.api.ops.executioner.DefaultOpExecutioner - Backend used: [CPU]; OS: [Linux] ... [main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 0 is 0.9707752535968273 [main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 100 is 0.3494968712782093 ... [main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 900 is 0.03135504326480282 ========================Evaluation Metrics======================== # of classes: 3 Accuracy: 0.9778 Precision: 0.9778 Recall: 0.9744 F1 Score: 0.9752 Precision, recall & F1: macro-averaged (equally weighted avg. of 3 classes) =========================Confusion Matrix========================= 0 1 2 ---------- 18 0 0 | 0 = 0 0 14 0 | 1 = 1 0 1 12 | 2 = 2 Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times ================================================================== real 0m5.856s user 0m25.638s sys 0m1.752s
同样,统计数据显示模型良好。在我们的测试数据集的混淆矩阵中有一个错误。DeepLearning4J 确实拥有令人印象深刻的技术范围,可以在某些场景中用于提高性能。对于这个示例,我启用了 AVX(高级矢量扩展)支持,但没有尝试使用 CUDA/GPU 支持,也没有利用任何 Apache Spark 集成。GPU 选项可能会加速应用程序,但考虑到数据集的大小和训练我们网络所需的计算量,它可能不会加速太多。对于这个小例子,为了访问原生 C++ 实现等而设置管道的开销,超过了收益。这些功能通常在处理更大的数据集或大量的计算时才能发挥作用;例如密集视频处理就会想到。
令人印象深刻的扩展选项的缺点是增加了复杂性。代码比我们在这篇博客中看到的其他技术稍微复杂一些,这是基于 API 中某些假设的,如果我们要使用 Spark 集成,即使我们这里没有使用,也需要这些假设。好消息是,一旦工作完成,如果我们确实想使用 Spark,那现在就相对简单了。
复杂性增加的另一个原因是类路径中所需的 jar 文件数量。我选择了使用 `nd4j-native-platform` 依赖项的简单选项,并添加了 `org.nd4j:nd4j-native:1.0.0-M2:linux-x86_64-avx2` 依赖项以支持 AVX。这让我的生活变得轻松,但引入了 170 多个 jar,其中许多用于不需要的平台。如果其他平台的用户也想尝试这个示例,拥有所有这些 jar 非常棒,但对于某些在某些平台上使用长命令行会中断的工具来说,可能会有点麻烦。如果这真的成为一个问题,我当然可以做更多的工作来缩小这些依赖列表。
Deep Netts
Deep Netts 是一家提供一系列与深度学习相关的产品和服务的公司。这里我们使用的是免费开源的Deep Netts 社区版纯 Java 深度学习库。它支持 Java 视觉识别 API (JSR381)。JSR381 的专家组于今年早些时候发布了最终规范,所以希望我们很快能看到更多兼容的实现。
我们使用 Deep Netts 进行鸢尾花分类的完整源代码在此,重要部分如下
var splits = dataSet.split(0.7d, 0.3d) // 70/30% split
var train = splits[0]
var test = splits[1]
var neuralNet = FeedForwardNetwork.builder()
.addInputLayer(numInputs)
.addFullyConnectedLayer(5, ActivationType.TANH)
.addOutputLayer(numOutputs, ActivationType.SOFTMAX)
.lossFunction(LossType.CROSS_ENTROPY)
.randomSeed(456)
.build()
neuralNet.trainer.with {
maxError = 0.04f
learningRate = 0.01f
momentum = 0.9f
optimizer = OptimizerType.MOMENTUM
}
neuralNet.train(train)
new ClassifierEvaluator().with {
println "CLASSIFIER EVALUATION METRICS\n${evaluate(neuralNet, test)}"
println "CONFUSION MATRIX\n$confusionMatrix"
}当我们运行此命令时,我们看到
paulk@pop-os:/extra/projects/iris_encog$ time groovy -cp "build/lib/*" Iris.groovy 16:49:27.089 [main] INFO deepnetts.core.DeepNetts - ------------------------------------------------------------------------ 16:49:27.091 [main] INFO deepnetts.core.DeepNetts - TRAINING NEURAL NETWORK 16:49:27.091 [main] INFO deepnetts.core.DeepNetts - ------------------------------------------------------------------------ 16:49:27.100 [main] INFO deepnetts.core.DeepNetts - Epoch:1, Time:6ms, TrainError:0.8584314, TrainErrorChange:0.8584314, TrainAccuracy: 0.5252525 16:49:27.103 [main] INFO deepnetts.core.DeepNetts - Epoch:2, Time:3ms, TrainError:0.52278274, TrainErrorChange:-0.33564866, TrainAccuracy: 0.52820516 ... 16:49:27.911 [main] INFO deepnetts.core.DeepNetts - Epoch:3031, Time:0ms, TrainError:0.029988592, TrainErrorChange:-0.015680967, TrainAccuracy: 1.0 TRAINING COMPLETED 16:49:27.911 [main] INFO deepnetts.core.DeepNetts - Total Training Time: 820ms 16:49:27.911 [main] INFO deepnetts.core.DeepNetts - ------------------------------------------------------------------------ CLASSIFIER EVALUATION METRICS Accuracy: 0.95681506 (How often is classifier correct in total) Precision: 0.974359 (How often is classifier correct when it gives positive prediction) F1Score: 0.974359 (Harmonic average (balance) of precision and recall) Recall: 0.974359 (When it is actually positive class, how often does it give positive prediction) CONFUSION MATRIX none Iris-setosaIris-versicolor Iris-virginica none 0 0 0 0 Iris-setosa 0 14 0 0 Iris-versicolor 0 0 18 1 Iris-virginica 0 0 0 12 real 0m3.160s user 0m10.156s sys 0m0.483s
这比 DeepLearning4j 快,与 Encog 相似。考虑到我们的小数据集,这是意料之中的,并不能说明大型问题的性能。
另一个优点是依赖列表。它不像 Encog 那样是单个 jar,但相差不远。有 Encog jar,JSR381 VisRec API(在一个单独的 jar 中),以及一些日志 jar。
使用 GraalVM 的 Deep Netts
如果性能对我们很重要,我们可能需要考虑的另一项技术是 GraalVM。GraalVM 是一个高性能 JDK 发行版,旨在加速用 Java 和其他 JVM 语言编写的应用程序的执行。我们将看看如何创建我们的 Iris Deep Netts 应用程序的原生版本。我们使用了 GraalVM 22.1.0 Java 17 CE 和 Groovy 4.0.3。我们将只介绍基本步骤,但还有其他地方可以获取额外的设置信息和故障排除帮助,例如此处、此处和此处。
Groovy 有两种特性。它的动态特性支持通过元编程在运行时添加方法,并通过缺失方法拦截和其他技巧与方法分派处理进行交互。其中一些技巧大量使用了反射和动态类加载,并给 GraalVM 带来了问题,因为 GraalVM 试图在编译时确定尽可能多的信息。Groovy 的静态特性具有更有限的元编程能力,但允许生成更接近 Java 的字节码。幸运的是,我们的示例不依赖任何动态 Groovy 技巧。我们将使用静态模式进行编译
paulk@pop-os:/extra/projects/iris_encog$ groovyc -cp "build/lib/*" --compile-static Iris.groovy
接下来我们构建我们的原生应用程序
paulk@pop-os:/extra/projects/iris_encog$ native-image --report-unsupported-elements-at-runtime \ --initialize-at-run-time=groovy.grape.GrapeIvy,deepnetts.net.weights.RandomWeights \ --initialize-at-build-time --no-fallback -H:ConfigurationFileDirectories=conf/ -cp ".:build/lib/*" Iris
我们告诉 GraalVM 在运行时初始化 `GrapeIvy`(以避免在类路径中需要 Ivy jar,因为 Groovy 只会在我们使用 `@Grab` 语句时惰性加载这些类)。我们对 `RandomWeights` 类也做了同样的处理,以避免它在编译时被锁定在一个固定的随机种子中。
现在我们准备运行我们的应用程序了
paulk@pop-os:/extra/projects/iris_encog$ time ./iris ... CLASSIFIER EVALUATION METRICS Accuracy: 0.93460923 (How often is classifier correct in total) Precision: 0.96491224 (How often is classifier correct when it gives positive prediction) F1Score: 0.96491224 (Harmonic average (balance) of precision and recall) Recall: 0.96491224 (When it is actually positive class, how often does it give positive prediction) CONFUSION MATRIX none Iris-setosaIris-versicolor Iris-virginica none 0 0 0 0 Iris-setosa 0 21 0 0 Iris-versicolor 0 0 20 2 Iris-virginica 0 0 0 17 real 0m0.131s user 0m0.096s sys 0m0.029s
我们可以在这里看到速度显著提高。这很棒,但我们应该注意,使用 GraalVM 通常涉及一些棘手的调查,特别是对于默认具有动态特性的 Groovy。使用 Groovy 的静态特性时,Groovy 的一些功能将不可用,并且一些库可能会出现问题。例如,Deep Netts 的依赖项之一是 log4j2。在撰写本文时,使用 log4j2 和 GraalVM 仍然存在问题。我们排除了 `log4j-core` 依赖项,并使用 `log4j-to-slf4j` 和 `logback-classic` 来规避这个问题。
结论
我们已经看到了一些不同的库,用于使用 Groovy 执行深度学习分类。每个库都有其优点和缺点。当然,有多种选项可以满足人们对极速启动速度的需求,直到可扩展到云中大规模计算农场的选项。