
从 Apache Wayang 使用 TensorFlow

发布时间:2025-02-28 上午 09:30
 在之前的博客文章中,我们讨论了:
在之前的博客文章中,我们讨论了:
-
使用 Apache Wayang 跨平台机器学习和 Apache Spark 对威士忌风味特征进行聚类分析
-
使用 深度学习和 GraalVM 对鸢尾花进行分类
-
使用 Oracle 23ai 向量数据类型 对鸢尾花进行分类
让我们看看如何使用 Apache Wayang 和 TensorFlow 与 Groovy 对鸢尾花进行分类
我们将查看一个主要基于 Apache Wayang 仓库中 Java 测试的实现。
首先,我们将定义一个字符串常量到标签值的映射。
var LABEL_MAP = ["Iris-setosa": 0, "Iris-versicolor": 1, "Iris-virginica": 2]现在我们可以创建一个辅助方法来定义我们将使用的操作符,这些操作符用于将测试和训练 CSV 文件转换为我们的数据集。操作符是可以分配给处理平台的工作块。最终,我们将有一个由操作符组成的图,形成我们的工作计划。
def fileOperation(URI uri, boolean random) {
var textFileSource = new TextFileSource(uri.toString()) // (1)
var line2tupleOp = new MapOperator<>(line -> line.split(",").with{ // (2)
new Tuple(it[0..-2]*.toFloat() as float[], LABEL_MAP[it[-1]])
}, String, Tuple)
var mapData = new MapOperator<>(tuple -> tuple.field0, Tuple, float[]) // (3)
var mapLabel = new MapOperator<>(tuple -> tuple.field1, Tuple, Integer) // (3)
if (random) {
Random r = new Random()
var randomOp = new SortOperator<>(e -> r.nextInt(), String, Integer) // (4)
textFileSource.connectTo(0, randomOp, 0)
randomOp.connectTo(0, line2tupleOp, 0)
} else {
textFileSource.connectTo(0, line2tupleOp, 0)
}
line2tupleOp.connectTo(0, mapData, 0)
line2tupleOp.connectTo(0, mapLabel, 0)
new Tuple<>(mapData, mapLabel)
}-
TextFileSource将文本文件转换为行 -
line2tupleOp将一行转换为一个元组,其中包含field0中的float[]数据和field1中的Integer标签 -
我们还有
mapData和mapLabel操作符,用于从我们的元组中获取两个部分 -
我们可以选择性地随机排序传入的数据集
我们将使用该辅助方法创建我们的测试和训练数据源
var TEST_PATH = getClass().classLoader.getResource("iris_test.csv").toURI()
var TRAIN_PATH = getClass().classLoader.getResource("iris_train.csv").toURI()
var trainSource = fileOperation(TRAIN_PATH, true)
var testSource = fileOperation(TEST_PATH, false)我们现在可以编写脚本的其余部分。首先,我们将定义特征和标签
Operator trainData = trainSource.field0
Operator trainLabel = trainSource.field1
Operator testData = testSource.field0
Operator testLabel = testSource.field1接下来,我们将为我们的深度学习网络定义一个模型。请记住,此类网络有输入(特征)、一个或多个隐藏层以及输出(在本例中是标签)。
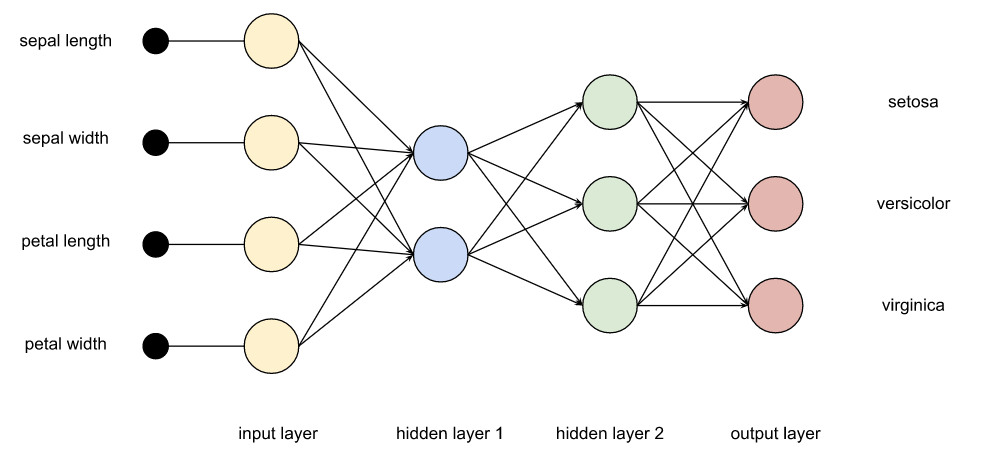
节点可以通过线性或非线性函数激活。
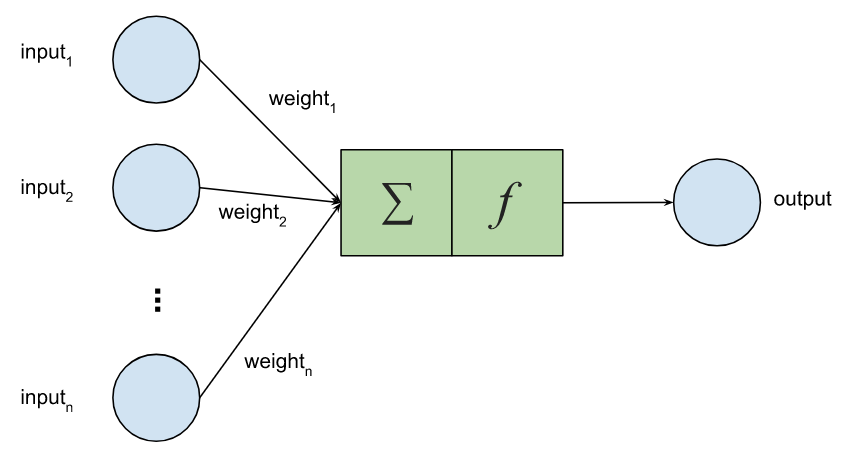
我们将有 4 个输入,连接到 32 个隐藏节点,再到 3 个输出,并使用 Sigmoid 激活。这些类都是平台无关的。在这里我们没有提及 TensorFlow,也没有使用任何 TensorFlow 类。
Op l1 = new Linear(4, 32, true)
Op s1 = new Sigmoid().with(l1.with(new Input(Input.Type.FEATURES)))
Op l2 = new Linear(32, 3, true).with(s1)
DLModel model = new DLModel(l2)我们定义了一个平台无关的深度学习训练操作符,提供了一些必要的选项,它将执行我们的训练。
Op criterion = new CrossEntropyLoss(3).with(
new Input(Input.Type.PREDICTED, Op.DType.FLOAT32),
new Input(Input.Type.LABEL, Op.DType.INT32)
)
Optimizer optimizer = new Adam(0.1f) // optimizer with learning rate
int batchSize = 45
int epoch = 10
var option = new DLTrainingOperator.Option(criterion, optimizer, batchSize, epoch)
option.setAccuracyCalculation(new Mean(0).with(
new Cast(Op.DType.FLOAT32).with(
new Eq().with(new ArgMax(1).with(
new Input(Input.Type.PREDICTED, Op.DType.FLOAT32)),
new Input(Input.Type.LABEL, Op.DType.INT32)
))))
var trainingOp = new DLTrainingOperator<>(model, option, float[], Integer)现在我们将定义更多操作符来计算和收集结果
var predictOp = new PredictOperator<>(float[], float[])
var bestFitOp = new MapOperator<>(array ->
array.indexed().max{ it.value }.key, float[], Integer)
var predicted = []
var predictedSink = createCollectingSink(predicted, Integer)
var groundTruth = []
var groundTruthSink = createCollectingSink(groundTruth, Integer)定义好操作符后,让我们将它们连接起来(定义我们的工作图)
trainData.connectTo(0, trainingOp, 0)
trainLabel.connectTo(0, trainingOp, 1)
trainingOp.connectTo(0, predictOp, 0)
testData.connectTo(0, predictOp, 1)
predictOp.connectTo(0, bestFitOp, 0)
bestFitOp.connectTo(0, predictedSink, 0)
testLabel.connectTo(0, groundTruthSink, 0)现在让我们将所有内容放入计划并执行
var wayangPlan = new WayangPlan(predictedSink, groundTruthSink)
new WayangContext().with {
register(Java.basicPlugin())
register(Tensorflow.plugin())
execute(wayangPlan)
}
println "predicted: $predicted"
println "ground truth: $groundTruth"
var correct = predicted.indices.count{ predicted[it] == groundTruth[it] }
println "test accuracy: ${correct / predicted.size()}"运行时我们得到以下输出
Start training: [epoch 1, batch 1] loss: 6.300267 accuracy: 0.111111 [epoch 1, batch 2] loss: 2.127365 accuracy: 0.488889 [epoch 1, batch 3] loss: 1.647756 accuracy: 0.333333 [epoch 2, batch 1] loss: 1.245312 accuracy: 0.333333 [epoch 2, batch 2] loss: 1.901310 accuracy: 0.422222 [epoch 2, batch 3] loss: 1.388500 accuracy: 0.244444 [epoch 3, batch 1] loss: 0.593732 accuracy: 0.888889 [epoch 3, batch 2] loss: 0.856900 accuracy: 0.466667 [epoch 3, batch 3] loss: 0.595979 accuracy: 0.755556 [epoch 4, batch 1] loss: 0.749081 accuracy: 0.666667 [epoch 4, batch 2] loss: 0.945480 accuracy: 0.577778 [epoch 4, batch 3] loss: 0.611283 accuracy: 0.755556 [epoch 5, batch 1] loss: 0.625158 accuracy: 0.666667 [epoch 5, batch 2] loss: 0.717461 accuracy: 0.577778 [epoch 5, batch 3] loss: 0.525020 accuracy: 0.600000 [epoch 6, batch 1] loss: 0.308523 accuracy: 0.888889 [epoch 6, batch 2] loss: 0.830118 accuracy: 0.511111 [epoch 6, batch 3] loss: 0.637414 accuracy: 0.600000 [epoch 7, batch 1] loss: 0.265740 accuracy: 0.888889 [epoch 7, batch 2] loss: 0.676369 accuracy: 0.511111 [epoch 7, batch 3] loss: 0.443011 accuracy: 0.622222 [epoch 8, batch 1] loss: 0.345936 accuracy: 0.666667 [epoch 8, batch 2] loss: 0.599690 accuracy: 0.577778 [epoch 8, batch 3] loss: 0.395788 accuracy: 0.755556 [epoch 9, batch 1] loss: 0.342955 accuracy: 0.688889 [epoch 9, batch 2] loss: 0.477057 accuracy: 0.933333 [epoch 9, batch 3] loss: 0.376597 accuracy: 0.822222 [epoch 10, batch 1] loss: 0.202404 accuracy: 0.888889 [epoch 10, batch 2] loss: 0.515777 accuracy: 0.600000 [epoch 10, batch 3] loss: 0.318649 accuracy: 0.911111 Finish training. predicted: [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2] ground truth: [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2] test accuracy: 1
在我们的用例中存在随机性因素,因此每次运行的结果可能会略有不同。
我们希望您对 Apache Groovy 和 Apache Wayang 有所了解!何不参与进来!