
Groovy™ 文本相似度


发布时间:2025-02-18 08:30PM
简介
让我们构建一个类似 Wordle 的猜词游戏。但是,我们不会告诉你多少字母正确和错位,我们会给你更多提示,但稍微不那么明显,使其更具挑战性!
我们甚至不会(直接)告诉你单词中有多少字母,但我们会给出以下提示:
你的猜测与隐藏单词听起来有多接近。
你的猜测与隐藏单词的含义有多接近。
我们将提供一些距离和相似度度量,而不是正确和错位的字母,这些度量将为你提供关于有多少正确字母、字母是否按顺序正确等线索。
因此,我们正在构思一个介于其他游戏之间的游戏。像 Wordle 一样猜单词的字母,但线索不那么直接,有点像 Master Mind 中的黑色钥匙钉表示你有一个彩色代码钉在正确位置,但你不知道是哪一个。它还将融入一些类似 Semantle 或 Proximity 等猜词游戏背后的思想,这些游戏也使用语义含义。
我们在这里的目标不是打磨一个生产就绪的游戏版本,而是:
-
让你深入了解字符串度量相似度算法(如最新 Apache Commons Text 版本中的算法)
-
让你深入了解语音相似度算法(如最新 Apache Commons Codec 版本中的算法)
-
让你深入了解由机器学习和深度神经网络驱动的语义文本相似度 (STS) 算法,使用 PyTorch、TensorFlow 和 Word2vec 等框架,以及大型语言模型 (LLM) 和 BERT 等技术
-
强调使用 Apache Groovy 玩转上述技术是多么容易
如果您是 Groovy 新手,请先查看此 Groovy 游戏构建教程。
背景
字符串相似度试图回答这个问题:一个单词(或短语、句子、段落、文档)是否与另一个相同或相似。这在许多涉及搜索、提问或调用命令的场景中都是一项重要功能。它可以帮助回答以下问题:
-
两个 Jira/GitHub 问题是同一问题的重复吗?
-
两个(或更多)客户记录实际上是同一个客户的吗?
-
某个社交媒体话题是否正在流行,因为即使多个帖子包含略有不同的词语,它们实际上是关于同一件事的?
-
即使客户的自然语言请求包含拼写错误,我能理解吗?
-
作为一名医生,我能找到一篇讨论患者医疗诊断/症状/治疗的医学期刊论文吗?
-
作为一名程序员,我能找到解决我的编码问题的方法吗?
在比较两件事是否相同时,我们通常希望加入一定程度的模糊性:
-
两个词除了大小写外都相同吗?例如
cat和Cat。 -
两个词除了拼写变体外都相同吗?例如
Clare、Claire和Clair。 -
两个词除了拼写错误或打字错误外都相同吗?例如
mathematiks和computter。 -
两个短语除了顺序和/或无关紧要的词语外都相同吗?例如
the red car和the car of colour red -
这些词听起来一样吗?例如
there、their和they’re -
这些词是意思相同(或相似)的变体吗?例如
cow、bull、calf、bovine、cattle或livestock
非常简单的情况通常可以手动明确处理,例如使用字符串库方法或正则表达式
assert 'Cat'.equalsIgnoreCase('cat')
assert ['color', 'Colour'].every { it =~ '[Cc]olou?r' }像这样明确处理情况很快就会变得繁琐。我们将研究一些可以帮助我们以更通用方式处理比较的库。
首先,我们将研究两个用于使用字符串度量执行相似度匹配的库:
-
info.debatty:java-string-similarity -
org.apache.commons:commons-textApache Commons Text
然后我们将研究一些用于语音匹配的库:
-
commons-codec:commons-codecApache Commons Codec for Soundex and Metaphone -
org.openrefine:mainOpenRefine for Metaphone3
然后我们将研究一些用于语义匹配的深度学习选项:
-
org.deeplearning4j:deeplearning4j-nlpfor GloVe, ConceptNet, and fastText models -
ai.djlwith Pytorch for a universal-sentence-encoder model and TensorFlow with an AnglE model
简单字符串度量
字符串度量提供了一种衡量单词(或短语)中字符相同程度的方法。这些算法通常计算相似度或距离(相似度的倒数)。两者是相关的。考虑 cat 与 hat。根据 Levenshtein 算法(稍后描述),将一个单词更改为另一个单词需要一次“编辑”。因此,我们说 cat 距 hat 的距离为 1。我们可以使用 (word_size - distance) / word_size 产生一个归一化的相似度值,其中 word_size 是两个单词中较大单词的大小。因此,我们将得到 Levenshtein 相似度度量为 2/3(或 0.67)。换句话说,cat 与 hat 相似度为 67%。
对于我们的游戏,有时我们需要距离,有时我们会使用相似度。
有许多教程(参见更多信息)描述了各种字符串度量算法。我们不会重复这些教程,但这里是一些常见算法的摘要:
| 算法 | 描述 |
|---|---|
将一个词转换为另一个词所需的最少“编辑”(插入、删除或替换)次数。 |
|
定义两个样本集之间的比率。这可以是单词中的字符集、句子中的单词集或短语中 |
|
与 Levenshtein 相似,但不允许插入和删除。 |
|
两个单词中按顺序出现的字符的最大数量,不一定连续。 |
|
这是一种也测量编辑距离的度量,但权重编辑以有利于具有共同前缀的单词。 |
你可能想知道这些算法有什么实际用途。这里只是一些用例:
-
最长公共子序列是流行
diff工具背后的算法 -
Hamming 距离是设计错误检测、错误纠正和校验和算法时的重要度量
-
Levenshtein 用于搜索引擎(如 Apache Lucene 和 Apache Solr)进行模糊匹配搜索和拼写纠正软件
事实上,Groovy 有一个使用 Damerau-Levenshtein 距离度量的内置示例。这种变体将原始单词中两个相邻字符的转置算作一次“编辑”。fish 和 ifsh 的 Levenshtein 距离是 2。fish 和 ifsh 的 Damerau-Levenshtein 距离是 1。
例如,对于这段代码
'foo'.toUpper()Groovy 将给出以下错误消息
No signature of method: java.lang.String.toUpper() is applicable for argument types: () values: [] Possible solutions: toUpperCase(), toURI(), toURL(), toURI(), toURL(), toSet()
而这段代码
'foo'.touppercase()给出此错误
No signature of method: java.lang.String.touppercase() is applicable for argument types: () values: [] Possible solutions: toUpperCase(), toUpperCase(java.util.Locale), toLowerCase(), toLowerCase(java.util.Locale)
作为可能解决方案返回的值是根据 Damerau-Levenshtein 距离为 String 类找到的最佳方法,但增加了一些智能以适应最接近的匹配参数。这包括 Groovy 的 String 扩展方法和(如果使用动态元编程)在运行时添加的任何方法。
|
注意
|
您会经常从 IDE 或 Groovy 编译器(启用静态检查时)收到有关使用不正确方法的反馈。但拥有此反馈提供了很好的备用方案,尤其是在 IDE 之外使用 Groovy 脚本时。 |
现在让我们看一些运行各种字符串度量算法的示例。我们将使用 Apache Commons Text 和 info.debatty:java-string-similarity 库中的算法。
这两个库都支持许多字符串度量类。提供了计算相似度和距离的方法。我们将依次查看两者。
首先,让我们看一些相似度度量。这些度量通常范围从 0(表示不相似)到 1(表示相同)。
我们将查看这两个库中相似度度量的以下子集。请注意,这两个库之间存在相当大的重叠。我们将在这两个库之间进行一些交叉检查,但不会详尽地比较它们。
var simAlgs = [
NormalizedLevenshtein: new NormalizedLevenshtein()::similarity,
'Jaccard (debatty k=1)': new Jaccard(1)::similarity,
'Jaccard (debatty k=2)': new Jaccard(2)::similarity,
'Jaccard (debatty k=3)': new Jaccard()::similarity,
'Jaccard (commons text k=1)': new JaccardSimilarity()::apply,
'JaroWinkler (debatty)': new JaroWinkler()::similarity,
'JaroWinkler (commons text)': new JaroWinklerSimilarity()::apply,
RatcliffObershelp: new RatcliffObershelp()::similarity,
SorensenDice: new SorensenDice()::similarity,
Cosine: new Cosine()::similarity,
]在示例代码中,我们对以下对运行这些度量:
var pairs = [
['there', 'their'],
['cat', 'hat'],
['cat', 'kitten'],
['cat', 'dog'],
['bear', 'bare'],
['bear', 'bean'],
['pair', 'pear'],
['sort', 'sought'],
['cow', 'bull'],
['winners', 'grinners'],
['knows', 'nose'],
['ground', 'aground'],
['grounds', 'aground'],
['peeler', 'repeal'],
['hippo', 'hippopotamus'],
['elton john', 'john elton'],
['elton john', 'nhoj notle'],
['my name is Yoda', 'Yoda my name is'],
['the cat sat on the mat', 'the fox jumped over the dog'],
['poodles are cute', 'dachshunds are delightful']
]我们可以按如下方式对我们的对运行算法:
pairs.each { wordPair ->
var results = simAlgs.collectValues { alg -> alg(*wordPair) }
// display results ...
}这是第一对的输出
there VS their JaroWinkler (commons text) 0.91 ██████████████████ JaroWinkler (debatty) 0.91 ██████████████████ Jaccard (debatty k=1) 0.80 ████████████████ Jaccard (commons text k=1) 0.80 ████████████████ RatcliffObershelp 0.80 ████████████████ NormalizedLevenshtein 0.60 ████████████ Cosine 0.33 ██████ Jaccard (debatty k=2) 0.33 ██████ SorensenDice 0.33 ██████ Jaccard (debatty k=3) 0.20 ████
我们已将图表中的条形图颜色编码为 80% 及以上为绿色,将其视为相似度方面的“匹配”。您可以根据用例选择不同的匹配阈值。
我们可以看到不同的算法对这两个词的相似度排名不同。
我们不显示所有算法对所有对的结果,只显示一些亮点,这些亮点可以让我们深入了解哪些相似度度量对我们的游戏最有用。
第一个观察是 Jaccard 算法在 k=1 时(查看单个字母集)的有用性。这里我们可以想象 bear 可能是我们的猜测,而 bare 可能是隐藏的单词。
bear VS bare
Jaccard (debatty k=1) 1.00 ████████████████████
在这里我们知道我们已经正确猜出了所有字母!
再举一个例子:
cow VS bull
Jaccard (debatty k=1) 0.00 ▏
我们可以排除我们猜测中的所有字母!
Jaccard 算法在查看多字母序列时如何?嗯,如果你试图确定社交媒体账户 @elton_john 是否与电子邮件 john.elton@gmail.com 是同一个人,那么 Jaccard 算法的更高索引将会有所帮助。
elton john VS john elton Jaccard (debatty k=1) 1.00 ████████████████████ Jaccard (debatty k=2) 0.80 ████████████████ Jaccard (debatty k=3) 0.45 █████████ elton john VS nhoj notle Jaccard (debatty k=1) 1.00 ████████████████████ Jaccard (debatty k=2) 0.00 ▏ Jaccard (debatty k=3) 0.00 ▏
请注意,对于“Elton John”反向,Jaccard 随着 k 值的增加而迅速下降到零,但只是交换单词(像我们的社交媒体账户和删除标点符号的电子邮件)仍然很高。因此,Jaccard 的更高 k 值肯定有其用途,但可能不需要用于我们的游戏。处理 k 个连续字母(也称为 n 个连续字母)很常见。实际上,对于此类序列有一个特殊术语:n-gram。虽然 n-gram 在衡量相似度方面发挥着重要作用,但它对我们的游戏并没有增加太多价值。因此,我们只在游戏中使用 k=1 的 Jaccard 算法。
现在让我们看看 JaroWinkler。此度量考虑了编辑次数,但计算了一个加权分数,惩罚了开头的更改,这反过来意味着具有共同前缀的单词具有更高的相似度分数。
如果我们看单词“superstar”和“supersonic”,11 个不同字母中有 5 个是共同的(因此 Jaccard 分数为 5/11 或 0.45),但由于它们都以相同的 6 个字母开头,因此 JaroWinkler 值为 0.90,得分很高。
交换为“partnership”和“leadership”,11 个不同字母中有 7 个是共同的,因此 Jaccard 分数更高,为 0.64,但即使它们都以相同的 6 个字符结尾,它也给我们一个较低的 JaroWinkler 分数,为 0.73。
superstar VS supersonic JaroWinkler (debatty) 0.90 ██████████████████ Jaccard (debatty k=1) 0.45 █████████ partnership VS leadership JaroWinkler (debatty) 0.73 ██████████████ Jaccard (debatty k=1) 0.64 ████████████
也许知道我们猜测的开头是否接近隐藏的单词会很有趣。所以我们将在游戏中使用 JaroWinkler 度量。
现在让我们切换到距离度量。
让我们首先探索我们可用的距离度量范围
var distAlgs = [
NormalizedLevenshtein: new NormalizedLevenshtein()::distance,
'WeightedLevenshtein (t is near r)': new WeightedLevenshtein({ char c1, char c2 ->
c1 == 't' && c2 == 'r' ? 0.5 : 1.0
})::distance,
Damerau: new Damerau()::distance,
OptimalStringAlignment: new OptimalStringAlignment()::distance,
LongestCommonSubsequence: new LongestCommonSubsequence()::distance,
MetricLCS: new MetricLCS()::distance,
'NGram(2)': new NGram(2)::distance,
'NGram(4)': new NGram(4)::distance,
QGram: new QGram(2)::distance,
CosineDistance: new CosineDistance()::apply,
HammingDistance: new HammingDistance()::apply,
JaccardDistance: new JaccardDistance()::apply,
JaroWinklerDistance: new JaroWinklerDistance()::apply,
LevenshteinDistance: LevenshteinDistance.defaultInstance::apply,
]并非所有这些度量都已归一化,因此像以前那样绘制图表并不那么有用。相反,我们将有一组预定义的短语(类似于搜索引擎的索引),我们将找到与某个查询最接近的短语。
这是我们预定义的短语
var phrases = [
'The sky is blue',
'The blue sky',
'The blue cat',
'The sea is blue',
'Blue skies following me',
'My ferrari is red',
'Apples are red',
'I read a book',
'The wind blew',
'Numbers are odd or even',
'Red noses',
'Read knows',
'Hippopotamus',
]现在,让我们使用查询 The blue car。我们将计算查询到每个候选短语的距离,并返回最接近的三个。这是 The blue car 的结果
NormalizedLevenshtein: The blue cat (0.08), The blue sky (0.25), The wind blew (0.62) WeightedLevenshtein (t is near r): The blue cat (0.50), The blue sky (3.00), The wind blew (8.00) Damerau: The blue cat (1.00), The blue sky (3.00), The wind blew (8.00) OptimalStringAlignment: The blue cat (1.00), The blue sky (3.00), The wind blew (8.00) LongestCommonSubsequence (debatty): The blue cat (2.00), The blue sky (6.00), The sky is blue (11.00) MetricLCS: The blue cat (0.08), The blue sky (0.25), The wind blew (0.46) NGram(2): The blue cat (0.04), The blue sky (0.21), The wind blew (0.58) NGram(4): The blue cat (0.02), The blue sky (0.13), The wind blew (0.50) QGram: The blue cat (2.00), The blue sky (6.00), The sky is blue (11.00) CosineDistance: The blue sky (0.33), The blue cat (0.33), The sky is blue (0.42) HammingDistance: The blue cat (1), The blue sky (3), Hippopotamus (12) JaccardDistance: The blue cat (0.18), The sea is blue (0.33), The blue sky (0.46) JaroWinklerDistance: The blue cat (0.03), The blue sky (0.10), The wind blew (0.32) LevenshteinDistance: The blue cat (1), The blue sky (3), The wind blew (8) LongestCommonSubsequenceDistance (commons text): The blue cat (2), The blue sky (6), The sky is blue (11)
作为另一个例子,让我们查询 Red roses
NormalizedLevenshtein: Red noses (0.11), Read knows (0.50), Apples are red (0.71) WeightedLevenshtein (t is near r): Red noses (1.00), Read knows (5.00), The blue sky (9.00) Damerau: Red noses (1.00), Read knows (5.00), The blue sky (9.00) OptimalStringAlignment: Red noses (1.00), Read knows (5.00), The blue sky (9.00) MetricLCS: Red noses (0.11), Read knows (0.40), The blue sky (0.67) NGram(2): Red noses (0.11), Read knows (0.55), Apples are red (0.75) NGram(4): Red noses (0.11), Read knows (0.53), Apples are red (0.82) QGram: Red noses (4.00), Read knows (13.00), Apples are red (15.00) CosineDistance: Red noses (0.50), The sky is blue (1.00), The blue sky (1.00) HammingDistance: Red noses (1), The sky is blue (-), The blue sky (-) JaccardDistance: Red noses (0.25), Read knows (0.45), Apples are red (0.55) JaroWinklerDistance: Red noses (0.04), Read knows (0.20), The sea is blue (0.37) LevenshteinDistance: Red noses (1), Read knows (5), The blue sky (9) LongestCommonSubsequenceDistance (commons text): Red noses (2), Read knows (7), The blue sky (13)
让我们检查一下这些结果。首先,对于大多数人来说,度量太多,无法轻松理解。我们希望将集合缩小。
我们展示了各种 Levenshtein 值。有些是实际的“编辑”距离,有些是度量。对于我们的游戏,由于我们最初不知道单词的长度,我们认为知道确切的编辑次数可能很有用。归一化值为 0.5 可能意味着 2 个字母的单词中有一个字母错误,4 个字母的单词中有两个字母错误,6 个字母的单词中有三个字母错误,等等。
我们还认为实际的距离度量可能是 Wordle 玩家可以理解的。一旦你知道隐藏单词的大小,距离间接给你正确字母的数量(这是 Wordle 玩家习惯的——只是这里我们不知道具体哪些字母是正确的)。
我们还考虑了 Damerau-Levenshtein。它允许相邻字符的转置,虽然这在大多数拼写检查场景中增加了价值,但对于我们的游戏,可能更难理解这种额外可能更改的距离度量意味着什么。
因此,我们将在游戏中使用标准的 Levenshtein 距离。
添加到我们列表中的最后一个度量是最长公共子序列。让我们看一些例子来突出我们为什么这样思考:
bat vs tab: LongestCommonSubsequence (1), Jaccard (3/3) back vs buck: LongestCommonSubsequence (3) Jaccard (3/5)
对于 bat vs tab,Jaccard 相似度为 100%,告诉我们猜测包含隐藏单词的所有(不同)字母。LCS 值为 1,告诉我们没有两个字母以正确的顺序出现。唯一可能的是字母以相反的顺序出现。
对于 back vs buck,LCS 为 3 结合 Jaccard 为 3/5 告诉我们三个共享字母也以相同的顺序出现在猜测和隐藏单词中。
我们将在游戏中使用最长公共子序列距离来捕获一些排序信息。
语音算法
语音算法将单词映射到其发音的表示形式。它们通常用于拼写检查器、搜索、数据去重和语音到文本系统。
最早的语音算法之一是 Soundex。其思想是,尽管拼写有细微差异,但发音相似的单词将具有相同的 Soundex 编码,例如 Claire、Clair 和 Clare 都具有相同的 Soundex 编码。Soundex 的概要是(除了首字母外)元音被删除,发音相似的辅音被归为一组。Commons Codec 有几种 Soundex 算法。英语中最常用的算法如下所示:
Pair Soundex RefinedSoundex DaitchMokotoffSoundex cat|hat C300|H300 C306|H06 430000|530000 bear|bare B600|B600 B109|B1090 790000|790000 pair|pare P600|P600 P109|P1090 790000|790000 there|their T600|T600 T6090|T609 390000|390000 sort|sought S630|S230 S3096|S30406 493000|453000 cow|bull C000|B400 C30|B107 470000|780000 winning|grinning W552|G655 W08084|G4908084 766500|596650 knows|nose K520|N200 K3803|N8030 567400|640000 ground|aground G653|A265 G49086|A049086 596300|059630 peeler|repeal P460|R140 P10709|R90107 789000|978000 hippo|hippopotamus H100|H113 H010|H0101060803 570000|577364
另一种常见的语音算法是 Metaphone。这在概念上与 Soundex 相似,但使用更复杂的算法进行编码。有各种版本可用。Commons Codec 支持 Metaphone 和 Double Metaphone。openrefine 项目包含 Metaphone 3 的早期版本。
Pair Metaphone Metaphone(8) DblMetaphone(8) Metaphone3 cat|hat KT|HT KT|HT KT|HT KT|HT bear|bare BR|BR BR|BR PR|PR PR|PR pair|pare PR|PR PR|PR PR|PR PR|PR there|their 0R|0R 0R|0R 0R|0R 0R|0R sort|sought SRT|ST SRT|ST SRT|SKT SRT|ST cow|bull K|BL K|BL K|PL K|PL winning|grinning WNNK|KRNN WNNK|KRNNK ANNK|KRNNK ANNK|KRNNK knows|nose NS|NS NS|NS NS|NS NS|NS ground|aground KRNT|AKRN KRNT|AKRNT KRNT|AKRNT KRNT|AKRNT peeler|repeal PLR|RPL PLR|RPL PLR|RPL PLR|RPL hippo|hippopotamus HP|HPPT HP|HPPTMS HP|HPPTMS HP|HPPTMS
Commons Codec 包含一些额外的算法,包括 Nysiis 和 Caverphone。为了完整性,它们如下所示。
Pair Nysiis Caverphone2 cat|hat CAT|HAT KT11111111|AT11111111 bear|bare BAR|BAR PA11111111|PA11111111 pair|pare PAR|PAR PA11111111|PA11111111 there|their TAR|TAR TA11111111|TA11111111 sort|sought SAD|SAGT ST11111111|ST11111111 cow|bull C|BAL KA11111111|PA11111111 winning|grinning WANANG|GRANAN WNNK111111|KRNNK11111 knows|nose N|NAS KNS1111111|NS11111111 ground|aground GRAD|AGRAD KRNT111111|AKRNT11111 peeler|repeal PALAR|RAPAL PLA1111111|RPA1111111 hippo|hippopotamus HAP|HAPAPA APA1111111|APPTMS1111
Caverphone2 将 sort 与 sought 匹配很有用,但它没有将 knows 与 nose 匹配。总而言之,这些算法与 Metaphone 相比并没有提供任何引人注目的东西。
对于我们的游戏,我们不希望用户必须理解各种语音算法的编码算法。我们希望给他们一个度量,让他们知道他们的猜测与隐藏单词的发音有多接近。
Pair SoundexDiff Metaphone5LCS Metaphone5Lev cat|hat 75% 50% 50% bear|bare 100% 100% 100% pair|pare 100% 100% 100% there|their 100% 100% 100% sort|sought 75% 67% 67% cow|bull 50% 0% 0% winning|grinning 25% 60% 60% knows|nose 25% 100% 100% ground|aground 0% 80% 80% peeler|repeal 25% 67% 33% hippo|hippopotamus 50% 40% 40%
深入探讨
除了基于单词的单个字母或语音映射寻找相似性外,机器学习和深度学习试图关联具有相似语义含义的单词。这种方法将每个单词(或短语)映射到 n 维空间(称为词向量或词嵌入)。相关单词倾向于在该空间中聚集在相似的位置。通常使用基于规则、统计或神经网络的方法来执行嵌入,并使用余弦相似度等距离度量来查找相关单词(或短语)。
大型语言模型(LLM)研究人员将我们在此处进行的匹配任务称为语义文本相似度(STS)任务。我们不会深入探讨 NLP 理论的任何细节,但我们会简要解释一下。我们将研究几种模型,并将它们分为两组:
-
上下文无关方法侧重于适用于所有上下文(大致)的嵌入。我们将研究三种使用此方法的模型:Google Research 的 Word2vec、Stanford NLP 的 GloVe 和 Facebook Research 的 fastText。我们将使用 DeepLearning4J 来加载和使用这些模型。
-
上下文相关方法如果在已知上下文的情况下可以提供更准确的匹配,但需要更深入的分析。例如,如果我们看到“monopoly”,我们可能会想到一家没有竞争的公司。如果我们看到“money”,我们可能会想到货币。但如果我们同时看到这两个词,我们立即将上下文切换到棋盘游戏。再举一个例子,短语“What is your age?”和“How old are you?”应该高度匹配,即使“old”和“age”等单个词使用 word2vec 方法可能只有中等语义相似度。
我们将研究两种使用这种方法的模型。Universal AnglE 是一个基于 BERT/LLM 的句子嵌入模型,与 PyTorch 结合使用。Google 的 Universal Sentence Encoder 模型经过训练和优化,适用于大于单词长度的文本,例如句子、短语或短段落,并与 TensorFlow 结合使用。我们将使用 Deep Java Library 在 JDK 上加载和使用这两个模型。
fastText
许多 Word2Vec 库可以根据原始的 Google 实现将模型读写到标准文件格式。
例如,我们可以从 Gensim Python 库下载一些预训练模型,将它们转换为 Word2Vec 格式,然后用 DeepLearning4J 打开它们。
import gensim.downloader
glove_vectors = gensim.downloader.load('fasttext-wiki-news-subwords-300')
glove_vectors.save_word2vec_format("fasttext-wiki-news-subwords-300.bin", binary=True)这个 fastText 模型拥有 100 万个词向量,这些词向量在 Wikipedia 2017、UMBC webbase 语料库和 statmt.org 新闻数据集(160 亿个标记)上进行了训练。
我们只需将 fastText 模型序列化为我们的 Word2Vec 表示,然后就可以调用 similarity 和 wordsNearest 等方法,如下所示:
var modelName = 'fasttext-wiki-news-subwords-300.bin'
var path = Paths.get(ConceptNet.classLoader.getResource(modelName).toURI()).toFile()
Word2Vec model = WordVectorSerializer.readWord2VecModel(path)
String[] words = ['bull', 'calf', 'bovine', 'cattle', 'livestock', 'horse']
println """fastText similarity to cow: ${
words
.collectEntries { [it, model.similarity('cow', it)] }
.sort { -it.value }
.collectValues('%4.2f'::formatted)
}
Nearest words in vocab: ${model.wordsNearest('cow', 4)}
"""这会给出以下输出:
fastText similarity to cow: [bovine:0.72, cattle:0.70, calf:0.67, bull:0.67, livestock:0.61, horse:0.60] Nearest words in vocab: [cows, goat, pig, bovine]
我们有许多可用选项来可视化这些类型的结果。我们可以使用我们之前使用的条形图,或者像热力图这样的东西
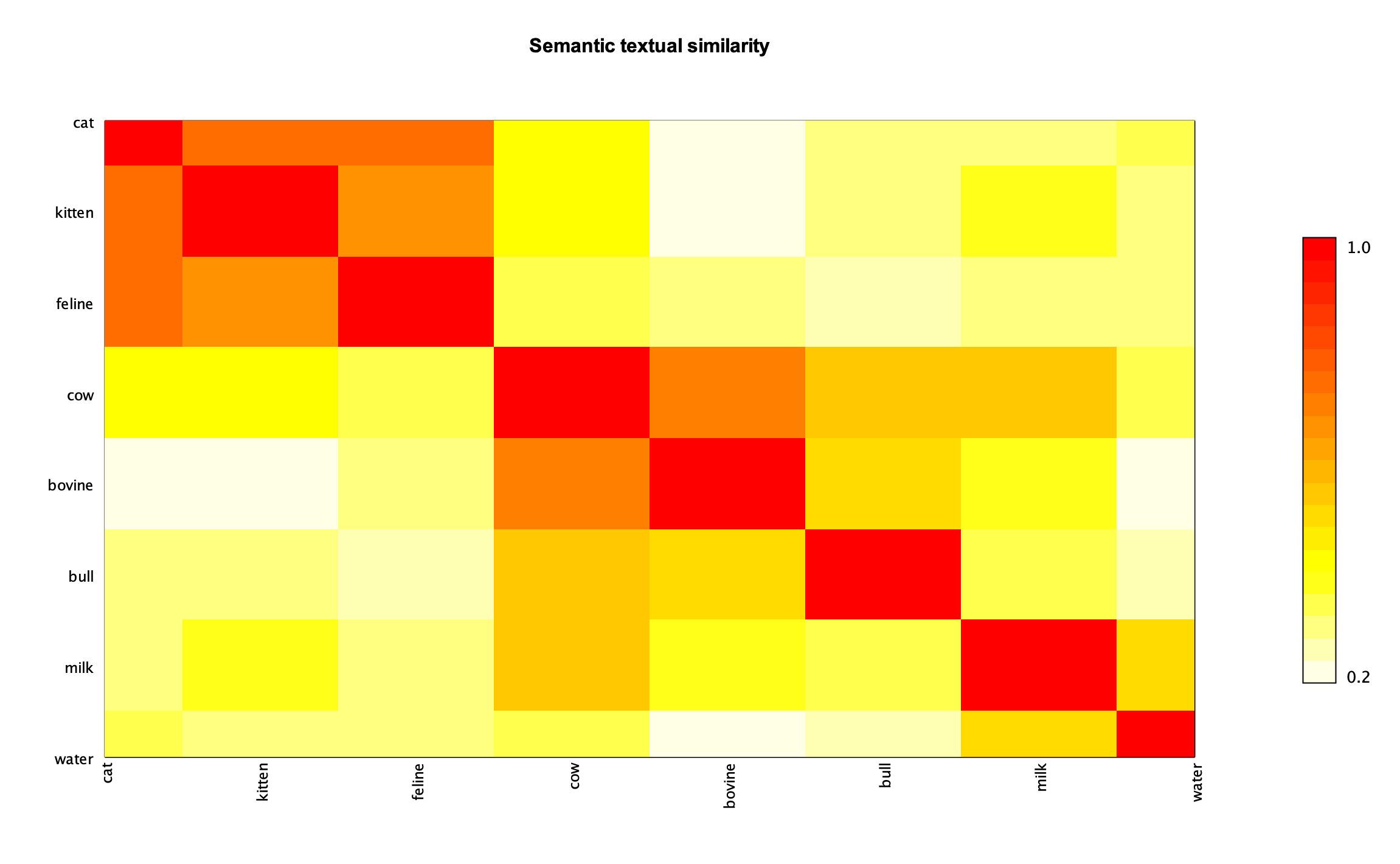
相似词的 agrupaciones 可以看作是较大的橙色和红色区域。我们还可以快速检查 cow 和 milk 之间的关系比 cow 和 water 之间的关系更强。
GloVe
我们可以通过简单地更改读取文件来切换到 GloVe 模型
var modelName = 'glove-wiki-gigaword-300.bin'使用此模型,脚本具有以下输出
GloVe similarity to cow: [bovine:0.67, cattle:0.62, livestock:0.47, calf:0.44, horse:0.42, bull:0.38] Nearest words in vocab: [cows, mad, bovine, cattle]
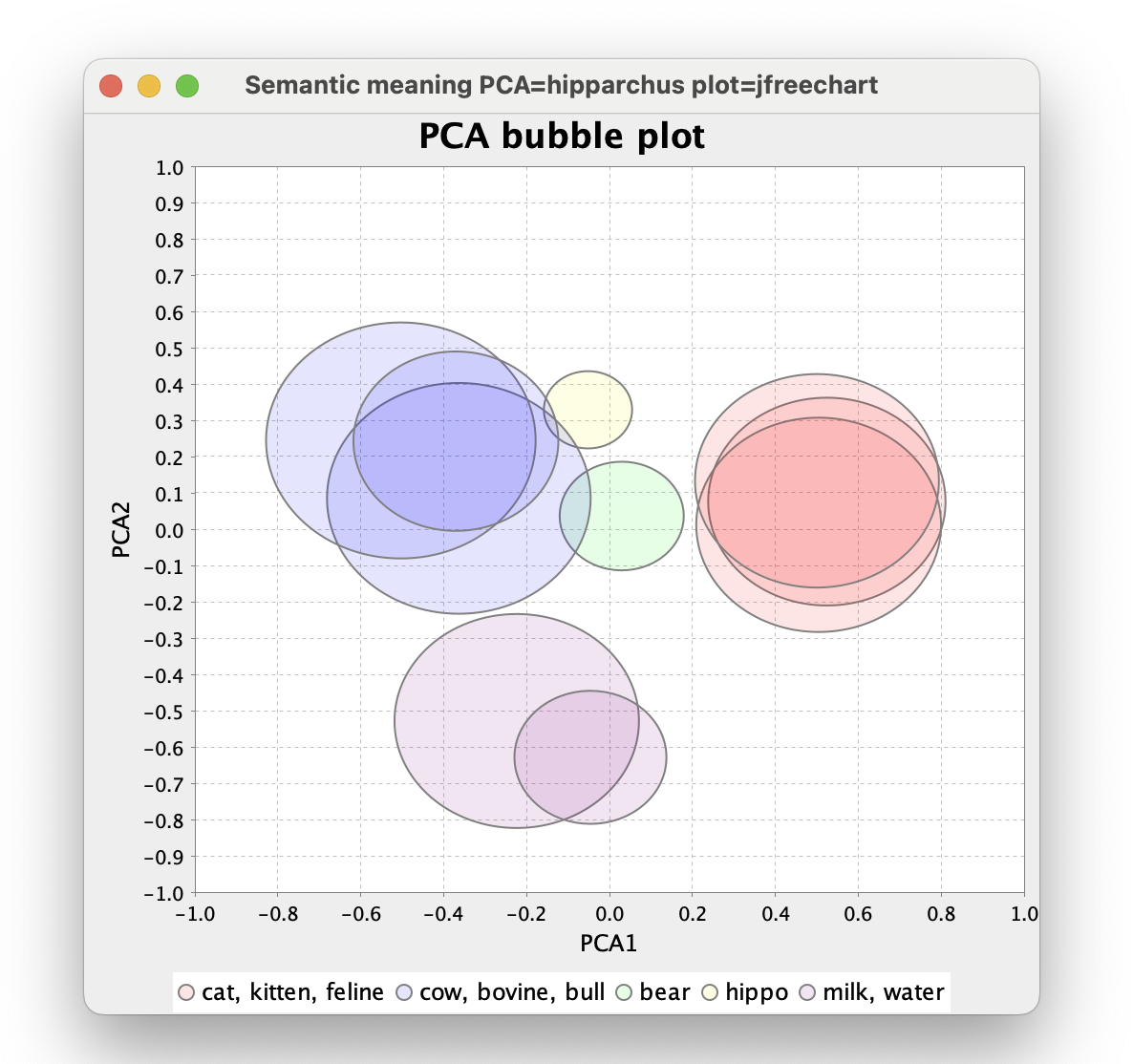
可视化词嵌入的另一种方法是将词向量显示为空间中的位置。然而,原始向量包含的维度太多,我们凡人无法理解。我们可以使用主成分分析 (PCA) 来减少维度,同时捕获最重要的信息,如下所示:
ConceptNet
同样,我们可以通过更改模型名称来切换到 ConceptNet 模型。该模型还支持多种语言,并将使用的语言合并到术语中,例如,对于英语,我们使用“/c/en/cow”而不是“cow”
var modelName = 'conceptnet-numberbatch-17-06-300.bin'
...
println """ConceptNet similarity to /c/en/cow: ${
words
.collectEntries { ["/c/en/$it", model.similarity('/c/en/cow', "/c/en/$it")] }
.sort { -it.value }
.collectValues('%4.2f'::formatted)
}
Nearest words in vocab: ${model.wordsNearest('/c/en/cow', 4)}
"""ConceptNet similarity to /c/en/cow: [/c/en/bovine:0.77, /c/en/cattle:0.77, /c/en/livestock:0.63, /c/en/bull:0.54, /c/en/calf:0.53, /c/en/horse:0.50] Nearest words in vocab: [/c/ast/vaca, /c/be/карова, /c/ur/گای, /c/gv/booa]
使用多语言模型有利有弊。模型本身更大,加载时间更长。它通常需要更多内存才能使用,但它确实允许我们考虑多语言选项,如果需要的话,如下所示:
Algorithm conceptnet
/c/fr/vache █████████
/c/de/kuh █████████
/c/en/cow /c/en/bovine ███████
/c/fr/bovin ███████
/c/en/bull █████
/c/fr/taureau █████████
/c/en/cow █████
/c/en/bull /c/fr/vache █████
/c/de/kuh █████
/c/fr/bovin █████
/c/de/kuh █████
/c/en/cow █████
/c/en/calf /c/fr/vache █████
/c/en/bovine █████
/c/fr/bovin █████
/c/fr/bovin █████████
/c/en/cow ███████
/c/en/bovine /c/de/kuh ███████
/c/fr/vache ███████
/c/en/calf █████
/c/en/bovine █████████
/c/fr/vache ███████
/c/fr/bovin /c/de/kuh ███████
/c/en/cow ███████
/c/fr/taureau █████
/c/en/cow █████████
/c/de/kuh █████████
/c/fr/vache /c/fr/bovin ███████
/c/en/bovine ███████
/c/fr/taureau █████
/c/en/bull █████████
/c/fr/bovin █████
/c/fr/taureau /c/fr/vache █████
/c/en/cow █████
/c/de/kuh █████
/c/en/cow █████████
/c/fr/vache █████████
/c/de/kuh /c/fr/bovin ███████
/c/en/bovine ███████
/c/en/calf █████
/c/en/cat ████████
/c/de/katze ████████
/c/en/kitten /c/en/bull ██
/c/en/cow █
/c/de/kuh █
/c/de/katze █████████
/c/en/kitten ████████
/c/en/cat /c/en/bull ██
/c/en/cow ██
/c/fr/taureau █
/c/en/cat █████████
/c/en/kitten ████████
/c/de/katze /c/en/bull ██
/c/de/kuh ██
/c/fr/taureau ██
我们不会将此功能用于我们的游戏,但如果您会多种语言或者您正在学习新语言,这将是一个很好的补充。
AnglE
我们将使用 Deep Java Library 及其 PyTorch 集成来加载和使用 AnglE 模型。该模型在 STS 领域获得多项最先进 (SOTA) 奖项。
与之前的模型不同,AnglE 支持概念嵌入。因此,我们可以输入短语而不仅仅是单词,它将根据该短语中单词用法的上下文信息匹配相似的短语。
因此,让我们准备一组示例短语,并尝试通过相似度找到与某些示例查询最接近的短语。代码如下所示:
var samplePhrases = [
'bull', 'bovine', 'kitten', 'hay', 'The sky is blue',
'The sea is blue', 'The grass is green', 'One two three',
'Bulls consume hay', 'Bovines convert grass to milk',
'Dogs play in the grass', 'Bulls trample grass',
'Dachshunds are delightful', 'I like cats and dogs']
var queries = [
'cow', 'cat', 'dog', 'grass', 'Cows eat grass',
'Poodles are cute', 'The water is turquoise']
var modelName = 'UAE-Large-V1.zip'
var path = Paths.get(DjlPytorchAngle.classLoader.getResource(modelName).toURI())
var criteria = Criteria.builder()
.setTypes(String, float[])
.optModelPath(path)
.optTranslatorFactory(new DeferredTranslatorFactory())
.optProgress(new ProgressBar())
.build()
var model = criteria.loadModel()
var predictor = model.newPredictor()
var sampleEmbeddings = samplePhrases.collect(predictor::predict)
queries.each { query ->
println "\n $query"
var queryEmbedding = predictor.predict(query)
sampleEmbeddings
.collect { cosineSimilarity(it, queryEmbedding) }
.withIndex()
.sort { -it.v1 }
.take(5)
.each { printf '%s (%4.2f)%n', samplePhrases[it.v2], it.v1 }
}对于每个查询,我们从示例短语中找到 5 个最接近的短语。运行时,结果如下所示(省略了库日志):
cow
bovine (0.86)
bull (0.73)
Bovines convert grass to milk (0.60)
hay (0.59)
Bulls consume hay (0.56)
cat
kitten (0.82)
I like cats and dogs (0.70)
bull (0.63)
bovine (0.60)
One two three (0.59)
dog
bull (0.69)
bovine (0.68)
I like cats and dogs (0.60)
kitten (0.58)
Dogs play in the grass (0.58)
grass
The grass is green (0.83)
hay (0.68)
Dogs play in the grass (0.65)
Bovines convert grass to milk (0.61)
Bulls trample grass (0.59)
Cows eat grass
Bovines convert grass to milk (0.80)
Bulls consume hay (0.69)
Bulls trample grass (0.68)
Dogs play in the grass (0.65)
bovine (0.62)
Poodles are cute
Dachshunds are delightful (0.63)
Dogs play in the grass (0.56)
I like cats and dogs (0.55)
bovine (0.49)
The grass is green (0.44)
The water is turquoise
The sea is blue (0.72)
The sky is blue (0.65)
The grass is green (0.53)
One two three (0.43)
bovine (0.39)
阿联酋
Deep Java Library 还集成了 TensorFlow,我们将用它来加载和使用 Google 的 USE 模型。
USE 模型也支持概念嵌入,所以我们将使用与 AnglE 相同的短语。
代码如下所示:
String[] samplePhrases = [
'bull', 'bovine', 'kitten', 'hay', 'The sky is blue',
'The sea is blue', 'The grass is green', 'One two three',
'Bulls consume hay', 'Bovines convert grass to milk',
'Dogs play in the grass', 'Bulls trample grass',
'Dachshunds are delightful', 'I like cats and dogs']
String[] queries = [
'cow', 'cat', 'dog', 'grass', 'Cows eat grass',
'Poodles are cute', 'The water is turquoise']
String tensorFlowHub = "https://storage.googleapis.com/tfhub-modules"
String modelUrl = "$tensorFlowHub/google/universal-sentence-encoder/4.tar.gz"
var criteria = Criteria.builder()
.optApplication(Application.NLP.TEXT_EMBEDDING)
.setTypes(String[], float[][])
.optModelUrls(modelUrl)
.optTranslator(new UseTranslator())
.optEngine("TensorFlow")
.optProgress(new ProgressBar())
.build()
var model = criteria.loadModel()
var predictor = model.newPredictor()
var sampleEmbeddings = predictor.predict(samplePhrases)
var queryEmbeddings = predictor.predict(queries)
queryEmbeddings.eachWithIndex { s, i ->
println "\n ${queries[i]}"
sampleEmbeddings
.collect { cosineSimilarity(it, s) }
.withIndex()
.sort { -it.v1 }
.take(5)
.each { printf '%s (%4.2f)%n', samplePhrases[it.v2], it.v1 }
}这是输出(省略了库日志):
cow
bovine (0.72)
bull (0.57)
Bulls consume hay (0.46)
hay (0.45)
kitten (0.44)
cat
kitten (0.75)
I like cats and dogs (0.39)
bull (0.35)
hay (0.31)
bovine (0.26)
dog
kitten (0.54)
Dogs play in the grass (0.45)
bull (0.39)
I like cats and dogs (0.37)
hay (0.35)
grass
The grass is green (0.61)
Bulls trample grass (0.56)
Dogs play in the grass (0.52)
hay (0.51)
Bulls consume hay (0.47)
Cows eat grass
Bovines convert grass to milk (0.60)
Bulls trample grass (0.58)
Dogs play in the grass (0.56)
Bulls consume hay (0.53)
bovine (0.44)
Poodles are cute
Dachshunds are delightful (0.54)
I like cats and dogs (0.42)
Dogs play in the grass (0.27)
Bulls consume hay (0.19)
bovine (0.16)
The water is turquoise
The sea is blue (0.56)
The grass is green (0.39)
The sky is blue (0.38)
kitten (0.17)
One two three (0.17)
比较算法选择
我们研究了 5 种不同的 STS 算法,但我们的游戏应该使用哪一种呢?
让我们看看所有 5 种算法对一些常见词的结果:
Algorithm angle use conceptnet glove fasttext
bovine ████████▏ bovine ███████▏ bovine ███████▏ bovine ██████▏ bovine ███████▏
cattle ████████▏ cattle ███████▏ cattle ███████▏ cattle ██████▏ cattle ███████▏
cow calf ████████▏ calf ██████▏ livestock ██████▏ milk ████▏ calf ██████▏
milk ███████▏ livestock ██████▏ bull █████▏ livestock ████▏ bull ██████▏
bull ███████▏ bull █████▏ calf █████▏ calf ████▏ milk ██████▏
bear ███████▏ cow █████▏ cow █████▏ cow ███▏ cow ██████▏
cow ███████▏ cattle █████▏ cattle █████▏ bear ███▏ cattle █████▏
bull cattle ███████▏ bovine █████▏ bovine ████▏ calf ███▏ bovine █████▏
bovine ███████▏ livestock ████▏ livestock ███▏ cattle ███▏ calf █████▏
calf ██████▏ calf ████▏ calf ███▏ cat ███▏ bear █████▏
bovine ████████▏ cow ██████▏ cow █████▏ cow ████▏ cow ██████▏
cow ████████▏ cattle ██████▏ bovine █████▏ bovine ███▏ cattle █████▏
calf cattle ███████▏ bovine █████▏ cattle ████▏ bull ███▏ bull █████▏
bear ██████▏ livestock █████▏ livestock ███▏ cattle ███▏ bovine █████▏
bull ██████▏ bull ████▏ bull ███▏ hippo ██▏ livestock █████▏
cow ████████▏ cattle ███████▏ cow ███████▏ cow ██████▏ cow ███████▏
cattle ████████▏ cow ███████▏ cattle ███████▏ cattle ████▏ cattle ██████▏
bovine calf ████████▏ livestock ██████▏ livestock ██████▏ feline ███▏ bull █████▏
livestock ███████▏ calf █████▏ calf █████▏ calf ███▏ calf █████▏
bull ███████▏ bull █████▏ bull ████▏ milk ██▏ livestock █████▏
bovine ████████▏ livestock ████████▏ livestock ████████▏ livestock ███████▏ livestock ████████▏
livestock ████████▏ bovine ███████▏ cow ███████▏ cow ██████▏ cow ███████▏
cattle cow ████████▏ cow ███████▏ bovine ███████▏ bovine ████▏ bovine ██████▏
calf ███████▏ calf ██████▏ bull █████▏ milk ███▏ calf █████▏
bull ███████▏ bull █████▏ calf ████▏ bull ███▏ bull █████▏
cattle ████████▏ cattle ████████▏ cattle ████████▏ cattle ███████▏ cattle ████████▏
bovine ███████▏ bovine ██████▏ cow ██████▏ cow ████▏ cow ██████▏
livestock cow ███████▏ cow ██████▏ bovine ██████▏ milk ███▏ water █████▏
bull ██████▏ calf █████▏ calf ███▏ water ██▏ bovine █████▏
calf ██████▏ bull ████▏ bull ███▏ bovine ██▏ calf █████▏
feline █████████▏ kitten ███████▏ kitten ████████▏ feline ████▏ kitten ███████▏
kitten ████████▏ feline ███████▏ feline ████████▏ kitten ████▏ feline ███████▏
cat bear ███████▏ bear ████▏ bull ██▏ cow ███▏ cow ████▏
milk ██████▏ cow ████▏ bear ██▏ bear ███▏ hippo ████▏
bull ██████▏ grass ███▏ cow ██▏ bull ███▏ bull ████▏
feline ████████▏ cat ███████▏ cat ████████▏ cat ████▏ cat ███████▏
cat ████████▏ feline ██████▏ feline ███████▏ feline ███▏ feline ██████▏
kitten bear ██████▏ cow ████▏ bear ██▏ hippo ██▏ hippo ████▏
milk █████▏ milk ████▏ bull ██▏ cow ██▏ cow ████▏
bovine █████▏ bear ███▏ hippo ██▏ calf ██▏ calf ████▏
cat █████████▏ cat ███████▏ cat ████████▏ cat ████▏ cat ███████▏
kitten ████████▏ kitten ██████▏ kitten ███████▏ kitten ███▏ kitten ██████▏
feline bear ██████▏ cow ███▏ bear ██▏ bovine ███▏ bovine ████▏
bovine ██████▏ livestock ███▏ hippo ██▏ hippo ██▏ hippo ████▏
bull ██████▏ grass ███▏ livestock ██▏ cow █▏ cow ████▏
bull ██████▏ cow ███▏ cow ███▏ calf ██▏ cow ████▏
calf ██████▏ feline ███▏ bovine ███▏ feline ██▏ calf ████▏
hippo bear ██████▏ bull ███▏ bear ██▏ kitten ██▏ kitten ████▏
bovine █████▏ bear ███▏ calf ██▏ bull ██▏ feline ████▏
cat █████▏ calf ███▏ bull ██▏ cow ██▏ cat ████▏
bull ███████▏ bare █████▏ bull ███▏ bull ███▏ bull █████▏
cat ███████▏ cat ████▏ hippo ██▏ cat ███▏ bare ████▏
bear bovine ██████▏ cow ████▏ feline ██▏ cow ██▏ kitten ████▏
calf ██████▏ bull ████▏ kitten ██▏ livestock ██▏ calf ████▏
milk ██████▏ kitten ███▏ cat ██▏ cattle ██▏ livestock ████▏
bear █████▏ bear █████▏ grass █▏ grass ██▏ bear ████▏
milk █████▏ calf ███▏ bear █▏ water ██▏ grass ████▏
bare green █████▏ cat ███▏ kitten ▏ green █▏ green ████▏
grass █████▏ grass ███▏ cat ▏ calf █▏ bull ███▏
water █████▏ green ███▏ cattle ▏ cat █▏ water ███▏
cow ███████▏ cow █████▏ cow █████▏ cow ████▏ cow ██████▏
bear ██████▏ water █████▏ bovine ███▏ water ████▏ water █████▏
milk bovine ██████▏ calf ████▏ cattle ███▏ cattle ███▏ cattle █████▏
cattle ██████▏ kitten ████▏ livestock ███▏ livestock ███▏ livestock █████▏
water ██████▏ bovine ████▏ water ██▏ bovine ██▏ calf █████▏
milk ██████▏ milk █████▏ milk ██▏ milk ████▏ milk █████▏
green ██████▏ grass ████▏ hippo ██▏ green ███▏ grass █████▏
water grass ██████▏ green ███▏ grass █▏ grass ██▏ livestock █████▏
cat ██████▏ cow ███▏ green █▏ livestock ██▏ green ████▏
bear █████▏ cat ███▏ livestock ▏ bare ██▏ cattle ████▏
green ███████▏ cow ████▏ green ███▏ green ███▏ green █████▏
water ██████▏ water ████▏ livestock ██▏ water ██▏ water █████▏
grass cat █████▏ livestock ████▏ water █▏ bare ██▏ livestock ████▏
livestock █████▏ calf ████▏ cattle █▏ livestock ██▏ cow ████▏
cattle █████▏ cattle ████▏ calf █▏ cattle ██▏ cattle ████▏
grass ███████▏ grass ███▏ grass ███▏ grass ███▏ grass █████▏
water ██████▏ water ███▏ water █▏ water ███▏ water ████▏
green cat ██████▏ cat ███▏ hippo █▏ milk ██▏ bare ████▏
bear ██████▏ bear ███▏ milk ▏ bear █▏ cow ███▏
feline █████▏ bare ███▏ bear ▏ cow █▏ bear ███▏
所有算法在识别相关词方面都表现良好,但这里有一些观察:
-
尽管 AnglE 和 USE 模型由于上下文原因可能提供更准确的匹配,但我们使用单个词的事实意味着没有上下文。所以它们可能对我们的游戏场景来说是多余的。
-
不同的模型对于“相关”的含义有不同的基线。例如,AnglE 对于具有“平均”语义关系的词语似乎徘徊在 40-50% 区域。ConceptNet 对于此类词语保持在 0% 左右,甚至可能变为负数。
-
在不同情况下,不同的模型在识别相似度方面表现更好,即似乎没有一个完美的模型总是优于其他模型。
从这些结果来看,如果我们要制作一个生产就绪的游戏,我们只会选择一个模型,可能选择 ConceptNet,而且我们可能会寻找一个仅限英语的模型,因为多语言模型是所有 5 个模型中加载时间最长的。但考虑到这篇文章的教育性质,我们将在游戏中包含所有 5 个模型的语义相似度度量。
玩游戏
游戏有一个非常简单的文本 UI。它运行在你的操作系统 shell、命令或控制台窗口或你的 IDE 中。游戏会随机选择一个未知大小的单词。你有 30 轮来猜隐藏的单词。每轮你可以输入一个单词,你将获得许多关于你的猜测与隐藏单词相似程度的度量。如果你花费太长时间,你将获得一些提示(稍后会详细介绍)。
让我们看看几轮游戏是什么样子,我们将为你提供一些关于我们在玩这些回合时使用的思考的评论。
第一轮
有许多带独特字母的长单词列表。一个通常有用的词是 aftershock。它有一些常见的元音和辅音。让我们从它开始。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 1): aftershock LongestCommonSubsequence 0 Levenshtein Distance: 10, Insert: 0, Delete: 3, Substitute: 7 Jaccard 0% JaroWinkler PREFIX 0% / SUFFIX 0% Phonetic Metaphone=AFTRXK 47% / Soundex=A136 0% Meaning AnglE 45% / Use 21% / ConceptNet 2% / GloVe -4% / fastText 19%
看起来我们真的搞砸了,但实际上这是个好消息。我们学到了什么?
-
我们实际上可以排除所有字母 A、F、T、E、R、S、H、O、C 和 K。如果 Jaccard 分数为 0%,游戏会自动为我们完成此操作;如果 Jaccard 分数为 100%,它会保留这些字母并丢弃所有其他字母。我们将看到“可能的字母”行发生变化。
-
因为我们删除了 3 个字母,我们知道隐藏的单词有 7 个字母。
-
尽管没有字母是正确的,但 Metaphone 分数不是 0,所以我们需要留意其他会转换为相同组的辅音。例如,Q 和 G 可以转换为 K,D 可以转换为 T。
就元音而言,除非是“rhythm”之类的词,否则 U 和 I 是我们最有可能的候选词。让我们浪费一回合来证实这个猜测。我们将选择一个包含这两个元音以及来自 aftershock 的混合辅音的词——我们不想让来自其他辅音的信息模糊我们可能学到的关于元音的信息。
Possible letters: b d g i j l m n p q u v w x y z Guess the hidden word (turn 2): fruit LongestCommonSubsequence 2 Levenshtein Distance: 6, Insert: 2, Delete: 0, Substitute: 4 Jaccard 22% JaroWinkler PREFIX 56% / SUFFIX 45% Phonetic Metaphone=FRT 39% / Soundex=F630 0% Meaning AnglE 64% / Use 41% / ConceptNet 37% / GloVe 31% / fastText 44%
我们学到了什么?
-
由于 LCS 是 2,U 和 I 都以该顺序出现在答案中,尽管可能存在其中一个或两个字母的重复。
-
Jaccard 的 22% 是 2 / 9。我们知道 F、R 和 T 不在隐藏单词中,所以 7 个字母的隐藏单词有 6 个不同的字母,即它有一个重复。
-
语义意义分数上升了,所以隐藏的单词与水果有一些关系。
一个常见的前缀是 ing,所有这些字母仍然是可能的。一些可能性是 jumping, dumping, guiding, bugging, bumping 和 mugging。但是,我们也知道只有一个重复字母,所以我们可以尝试 judging, pulling, budding, buzzing, bulging, piquing, pumping, mulling, numbing, 和 pudding (等等)。由于我们知道与水果存在某种语义关系,其中两个词脱颖而出。Budding 是果树需要做的事情,以便以后结出果实。Pudding 是一种食物。这是一个 50/50 的猜测。让我们尝试第一个。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 3): budding LongestCommonSubsequence 6 Levenshtein Distance: 1, Insert: 0, Delete: 0, Substitute: 1 Jaccard 71% JaroWinkler PREFIX 90% / SUFFIX 96% Phonetic Metaphone=BTNK 79% / Soundex=B352 75% Meaning AnglE 52% / Use 35% / ConceptNet 2% / GloVe 4% / fastText 25%
我们有 6 个字母连续正确,5 个不同的字母。此外,Metaphone 和 Soundex 分数很高,JaroWinkler 说我们猜测的前半部分很接近,后半部分非常接近。我们猜测的“pudding”听起来是正确的。我们试试看。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 4): pudding LongestCommonSubsequence 7 Levenshtein Distance: 0, Insert: 0, Delete: 0, Substitute: 0 Jaccard 100% JaroWinkler PREFIX 100% / SUFFIX 100% Phonetic Metaphone=PTNK 100% / Soundex=P352 100% Meaning AnglE 100% / Use 100% / ConceptNet 100% / GloVe 100% / fastText 100% Congratulations, you guessed correctly!
第二轮
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 1): bail LongestCommonSubsequence 1 Levenshtein Distance: 7, Insert: 4, Delete: 0, Substitute: 3 Jaccard 22% JaroWinkler PREFIX 42% / SUFFIX 46% Phonetic Metaphone=BL 38% / Soundex=B400 25% Meaning AnglE 46% / Use 40% / ConceptNet 0% / GloVe 0% / fastText 31%
-
由于 LCS 为 1,与隐藏词共享的字母以相反的顺序出现。
-
有 4 次插入和 0 次删除,这意味着隐藏的单词有 8 个字母。
-
Jaccard 的 22% 是 2/9。因此,隐藏单词中有 2 个字母在
bail中,有 5 个不在。 隐藏单词中有 7 个独特的字母。它有一个重复字母。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 2): leg LongestCommonSubsequence 2 Levenshtein Distance: 6, Insert: 5, Delete: 0, Substitute: 1 Jaccard 25% JaroWinkler PREFIX 47% / SUFFIX 0% Phonetic Metaphone=LK 38% / Soundex=L200 0% Meaning AnglE 50% / Use 18% / ConceptNet 11% / GloVe 13% / fastText 37%
-
Jaccard 的 2 / 8 告诉我们 'leg' 中的两个字母出现在隐藏词中。
-
LCS 为 2 告诉我们 它们以与隐藏词中相同的顺序出现。
-
JaroWinkler 的前缀得分很高,为 47%,但后缀得分却为 0%。这表明两个正确字母位于单词的开头附近。
-
Metaphone 识别出与编码 LK 的某些相似性,表明隐藏单词包含一些编码为“L”或“K”的辅音组。
让我们尝试一个开头附近有“L”和“G”的单词
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 3): languish LongestCommonSubsequence 2 Levenshtein Distance: 8, Insert: 0, Delete: 0, Substitute: 8 Jaccard 15% JaroWinkler PREFIX 50% / SUFFIX 50% Phonetic Metaphone=LNKX 34% / Soundex=L522 0% Meaning AnglE 46% / Use 12% / ConceptNet -11% / GloVe -4% / fastText 25%
-
8 次替换意味着 没有一个字母与 'languish' 处于相同位置。
让我们尝试一个以“L”和“E”开头的单词,最多带入“languish”中的两个字母
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 4): election LongestCommonSubsequence 5 Levenshtein Distance: 4, Insert: 0, Delete: 0, Substitute: 4 Jaccard 40% JaroWinkler PREFIX 83% / SUFFIX 75% Phonetic Metaphone=ELKXN 50% / Soundex=E423 75% Meaning AnglE 47% / Use 13% / ConceptNet -5% / GloVe -7% / fastText 26%
-
Jaccard 告诉我们我们有 4 个与隐藏词共享的不同字母,但我们的 LCS 为 5。 重复的“E”必须是正确的,并且所有正确字母的顺序必须与隐藏词匹配。
-
仅 4 次替换意味着 8-4=4 个字母在正确位置。
-
JaroWinkler 略微偏爱前缀而不是后缀,这表明不正确的字母可能更靠近结尾。
-
语音指标有所增加。例如,“languish”编码为 LNKX,得分仅为 34%,而“election”编码为 ELKXN,得分 50%。这两个指标都强烈表明隐藏词以 E 开头。
根据与 leg 的 LCS 为 2,隐藏词中要么是“L”、“E”要么是“E”、“G”。尝试“L”、“E”
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 5): elevator LongestCommonSubsequence 8 Levenshtein Distance: 0, Insert: 0, Delete: 0, Substitute: 0 Jaccard 100% JaroWinkler PREFIX 100% / SUFFIX 100% Phonetic Metaphone=ELFTR 100% / Soundex=E413 100% Meaning AnglE 100% / Use 100% / ConceptNet 100% / GloVe 100% / fastText 100% Congratulations, you guessed correctly!
第三轮
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 1): aftershock LongestCommonSubsequence 3 Levenshtein Distance: 8, Insert: 0, Delete: 4, Substitute: 4 Jaccard 50% JaroWinkler PREFIX 61% / SUFFIX 49% Phonetic Metaphone=AFTRXK 33% / Soundex=A136 25% Meaning AnglE 44% / Use 11% / ConceptNet -7% / GloVe 1% / fastText 15%
我们知道了什么?
-
我们删除了 4 个字母,所以隐藏的单词有 6 个字母
-
Jaccard 的 50% 是 5/10 或 6/12。如果是后者,我们将拥有所有字母,所以隐藏的单词中不可能有 2 个额外的字母,所以是 5/10。这意味着我们需要从 aftershock 中选择 5 个字母,重复其中一个,然后我们就拥有所有字母了
-
语音线索表明它可能不是以 A 开头
在 aftershock 中,F、H 和 K 可能是最不常见的。让我们从剩余的 7 个字母中选择一个 6 个字母的单词,并遵循我们的 LCS 线索。我们知道这不可能是正确的,因为我们还没有重复字母,但我们只是想缩小可能性。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 2): coarse LongestCommonSubsequence 3 Levenshtein Distance: 4, Insert: 0, Delete: 0, Substitute: 4 Jaccard 57% JaroWinkler PREFIX 67% / SUFFIX 67% Phonetic Metaphone=KRS 74% / Soundex=C620 75% Meaning AnglE 51% / Use 12% / ConceptNet 5% / GloVe 23% / fastText 26%
这告诉我们
-
我们现在有 5 个不同字母中的 4 个(我们应该丢弃 2 个)
-
语音学表明我们接近但不很接近,从 Metaphone 值 KRS 中,我们应该丢弃一个并保留两个。
我们假设 C 和 E 是错误的,并引入另一个常见字母 T。我们需要找到一个与先前猜测的 LCS 条件匹配的单词,并且我们将重复一个字母 S。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 3): roasts LongestCommonSubsequence 3 Levenshtein Distance: 6, Insert: 0, Delete: 0, Substitute: 6 Jaccard 67% JaroWinkler PREFIX 56% / SUFFIX 56% Phonetic Metaphone=RSTS 61% / Soundex=R232 25% Meaning AnglE 54% / Use 25% / ConceptNet 18% / GloVe 18% / fastText 31%
我们学到了
-
语音学下降了,所以 S 可能不是正确引入的字母,我们想要 K(来自字母 C)和 R(来自先前的猜测)。
-
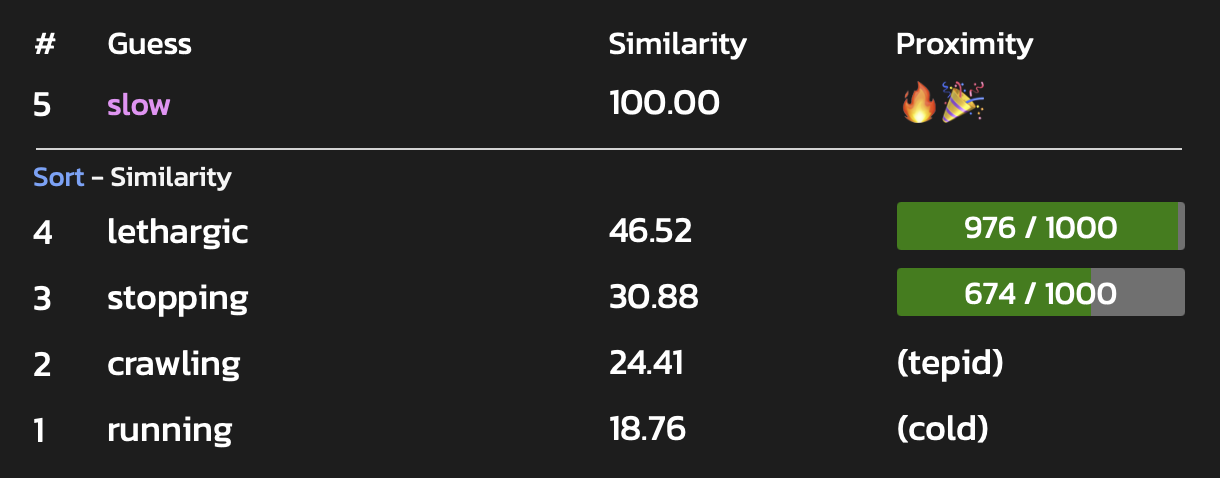
此外,语义含义已上升到“温暖”(相对于先前猜测的“冷”)。也许隐藏词与烤肉有关。
让我们尝试一个以 C 开头,与烤肉相关的词。
Possible letters: a b c d e f g h i j k l m n o p q r s t u v w x y z Guess the hidden word (turn 4): carrot LongestCommonSubsequence 6 Levenshtein Distance: 0, Insert: 0, Delete: 0, Substitute: 0 Jaccard 100% JaroWinkler PREFIX 100% / SUFFIX 100% Phonetic Metaphone=KRT 100% / Soundex=C630 100% Meaning AnglE 100% / Use 100% / ConceptNet 100% / GloVe 100% / fastText 100% Congratulations, you guessed correctly!
成功!
提示
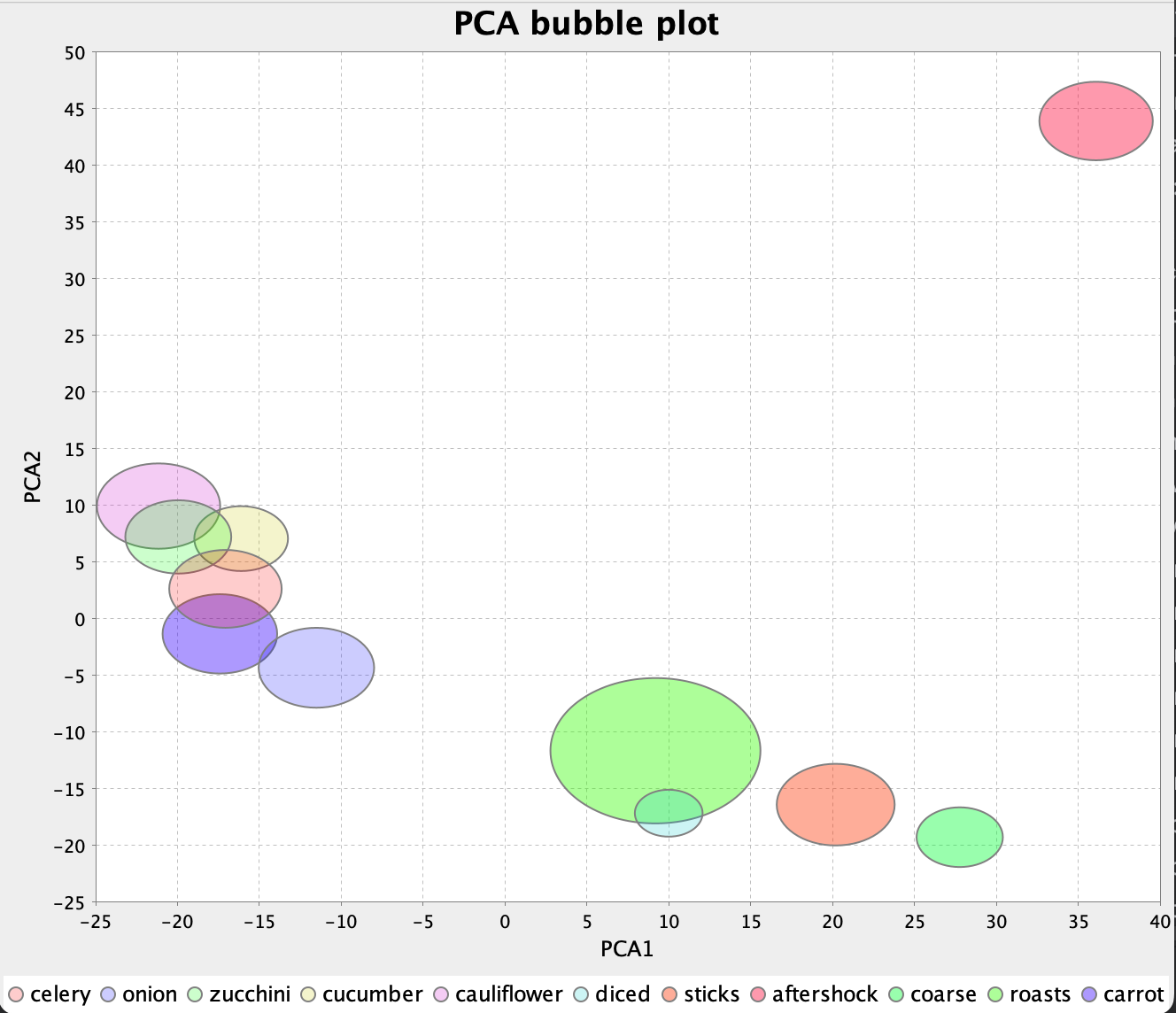
一些猜词游戏允许玩家请求提示。对于我们的游戏,我们决定定期提供提示,随着游戏的进行提供更强的提示。我们使用 wordsNearest 方法返回的 20 个最近相似词作为三个 word2vec 模型的输入,然后选择一个子集。
尽管在我们展示的游戏中不需要,但这是第三轮的提示。
After round 8: root_vegetable, daucus After round 16: diced, cauliflower, cucumber After round 24: celery, onion, sticks, zucchini

更多信息
本文的源代码
其他参考网站
相关库和链接