
使用 Groovy™ 的 Oracle 23ai 向量数据类型对鸢尾花进行分类
发布时间:2024-06-30 晚上 11:21

groovy-data-science 仓库中的Iris 项目专门用于此示例。它包含许多 Groovy 脚本和一个 Jupyter/BeakerX 笔记本,突出显示此示例,比较和对比了各种库和各种分类算法。
之前的一篇博客文章描述了使用多种深度学习库的此示例,并提供了一个利用 GraalVM 的解决方案。在这篇博客文章中,我们将探讨使用 Oracle 23ai 的向量数据类型和向量 AI 查询来分类我们数据集的一部分。
通常,许多机器学习/AI 算法处理信息向量。此类信息可能是实际数据值,如我们花的特征,或者是数据值的投影,或者是文本、视频、图像或声音文件重要信息的表示。后者通常称为嵌入。
对于我们来说,我们将找到具有相似特征的花朵。在其他相似性搜索场景中,我们可能会检测欺诈性交易,查找客户推荐,或者根据嵌入的“接近度”查找相似图像。
数据集
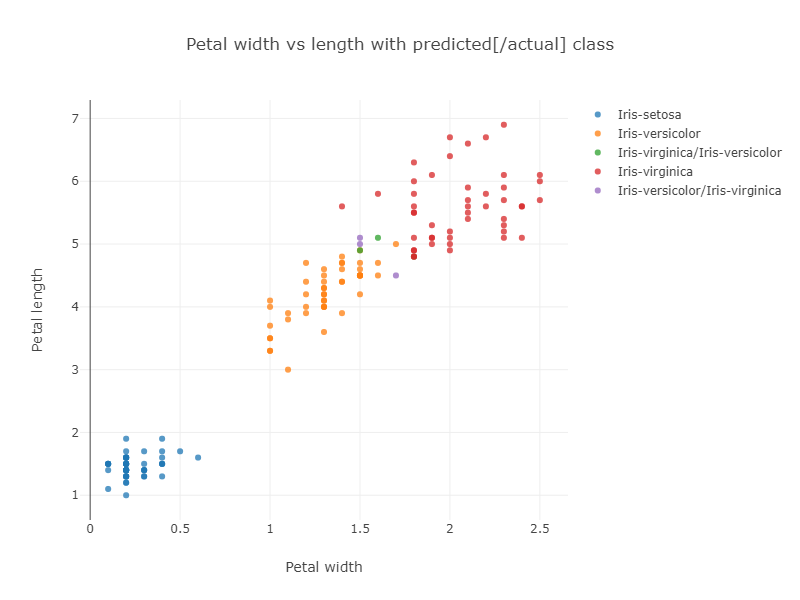
前面提到的Iris 项目展示了如何使用各种技术对 Iris 数据集进行分类。特别是,一个示例使用了Smile库的 kNN 分类算法。该示例使用整个数据集来训练模型,然后在整个数据集上运行模型以评估其准确性。该算法在弗吉尼亚鸢尾和变色鸢尾分组重叠附近的数据点上遇到了一些麻烦,如分类与花瓣大小的结果图所示
如果我们查看分类与萼片大小,我们可以看到更多的混淆可能性
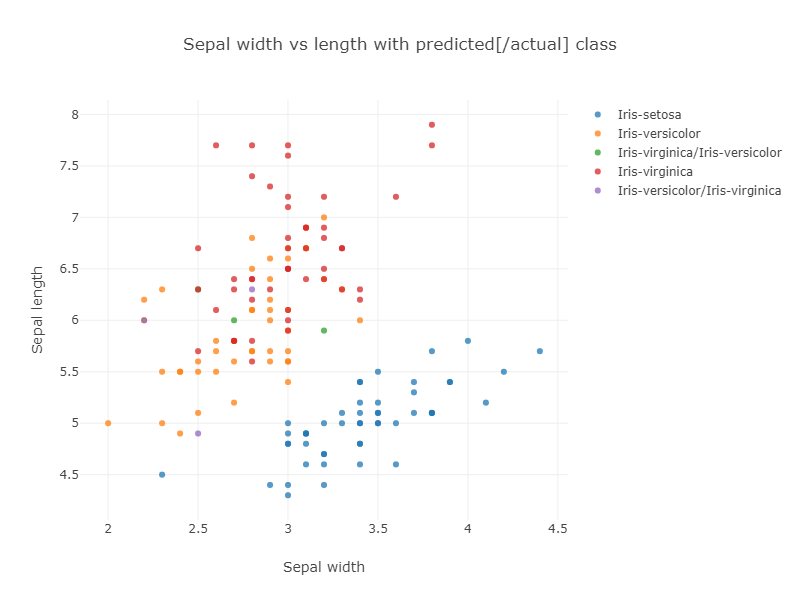
紫色和绿色的点表示被错误分类的花朵。
相应的混淆矩阵也显示了这些结果
Confusion matrix: ROW=truth and COL=predicted class 0 | 50 | 0 | 0 | class 1 | 0 | 47 | 3 | class 2 | 0 | 3 | 47 |
通常,在原始数据集上运行模型可能不理想,因为我们无法获得准确的错误计算,但它确实突出显示了我们数据的一些重要信息。在我们的例子中,我们可以看到弗吉尼亚鸢尾和变色鸢尾类别变得拥挤,并且靠近两个组重叠的数据点可能容易被错误分类。
数据库解决方案
我们的数据存储在一个 CSV 文件中
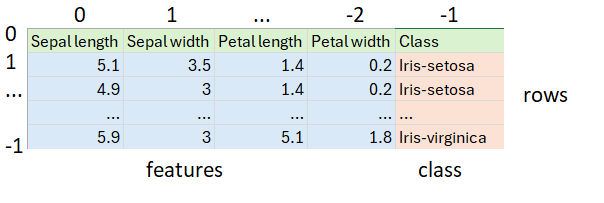
它恰好有三种鸢尾花,每种 50 个。首先,我们从 CSV 文件加载数据集,跳过标题行并打乱其余行,以确保我们将针对三种鸢尾花的随机混合进行测试
var file = getClass().classLoader.getResource('iris_data.csv').file as File
var rows = file.readLines()[1..-1].shuffled() // skip header and shuffle
var (training, test) = rows.chop(rows.size() * .8 as int, -1)打乱后,我们将数据分成两组。前 80% 将进入数据库。它对应于正常数据科学术语中的“训练”数据。后 20% 将对应于我们的“测试”数据。
接下来,我们定义 SQL 连接所需的信息
var url = 'jdbc:oracle:thin:@localhost:1521/FREEPDB1'
var user = 'some_user'
var password = 'some_password'
var driver = 'oracle.jdbc.driver.OracleDriver'接下来,我们创建数据库连接并使用它插入“训练”行,然后在“测试”行上进行测试
Sql.withInstance(url, user, password, driver) { sql ->
training.each { row ->
var data = row.split(',')
var features = data[0..-2].toString()
sql.executeInsert """
INSERT INTO Iris (class, features) VALUES (${data[-1]}, $features)
"""
}
printf "%-20s%-20s%-20s%n", 'Actual', 'Predicted', 'Confidence'
test.each { row ->
var data = row.split(',')
var features = VECTOR.ofFloat64Values(data[0..-2]*.toDouble() as double[])
var closest10 = sql.rows """
select class from Iris
order by vector_distance(features, $features, EUCLIDEAN)
fetch first 10 rows only
"""
var results = closest10
.groupBy{ e -> e.CLASS }
.collectEntries { e -> [e.key, e.value.size()]}
var predicted = results.max{ e -> e.value }
printf "%-20s%-20s%5d%n", data[-1], predicted.key, predicted.value * 10
}
}这段代码有一些有趣的方面。
-
当我们插入数据时,我们只使用了字符串。因为`features`列的类型已知,它会自动转换。
-
我们可以选择显式处理类型,如查询中所示,其中使用了 `VECTOR.ofFloat64Values`。
-
可能看起来奇怪的是,实际上没有像传统算法那样训练模型。相反,SQL 查询中的 `vector_distance` 函数调用基于 kNN 的搜索来查找结果。在我们的例子中,我们要求找到前 10 个最近的点。
-
我们在查询中使用了 `EUCLIDEAN` 距离度量,但如果我们选择 `EUCLIDEAN_SQUARED`,我们将获得相似的结果,且执行时间更快。直观地说,如果两个点彼此靠近,则两种度量都将很小,而如果两个点不相关,则两种度量都将很大。如果我们的特征特性是标准化的,我们预计会得到相同的结果。
-
`COSINE` 距离度量也表现出色。直观地说,如果重要的不是萼片和花瓣的实际大小,而是它们的比例,那么相似的花朵将在我们的 2D 图上处于相同的角度,而这正是 `COSINE` 所测量的。对于此数据集,两者都很重要,但任一测量都能得到所有(或几乎所有)正确结果。
-
一旦我们得到前 10 个最近的点,类别预测就是从 10 个结果中最常预测的类别。我们的置信度表示前 10 个中有多少与预测一致。
输出如下
Actual Predicted Confidence Iris-virginica Iris-virginica 90 Iris-virginica Iris-virginica 90 Iris-virginica Iris-virginica 100 Iris-virginica Iris-virginica 100 Iris-virginica Iris-versicolor 60 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-virginica Iris-virginica 100 Iris-versicolor Iris-versicolor 100 Iris-versicolor Iris-versicolor 100 Iris-versicolor Iris-versicolor 70 Iris-virginica Iris-virginica 100 Iris-virginica Iris-virginica 100 Iris-setosa Iris-setosa 100 Iris-versicolor Iris-versicolor 100 Iris-virginica Iris-virginica 100 Iris-versicolor Iris-versicolor 100 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-versicolor Iris-versicolor 100 Iris-virginica Iris-virginica 90 Iris-setosa Iris-setosa 100 Iris-virginica Iris-virginica 90 Iris-setosa Iris-setosa 100 Iris-setosa Iris-setosa 100 Iris-virginica Iris-virginica 100 Iris-virginica Iris-virginica 100
只有一个结果不正确(上面第一个**粗体**行)。由于我们随机打乱了数据,因此其他运行中可能会得到不同数量的不正确结果。
我们可以通过在 3D 图中绘制最近的 10 个点来可视化距离查询的工作方式。我们将对 70% 置信度情况下返回的点(上面第二个**粗体**行)进行此操作
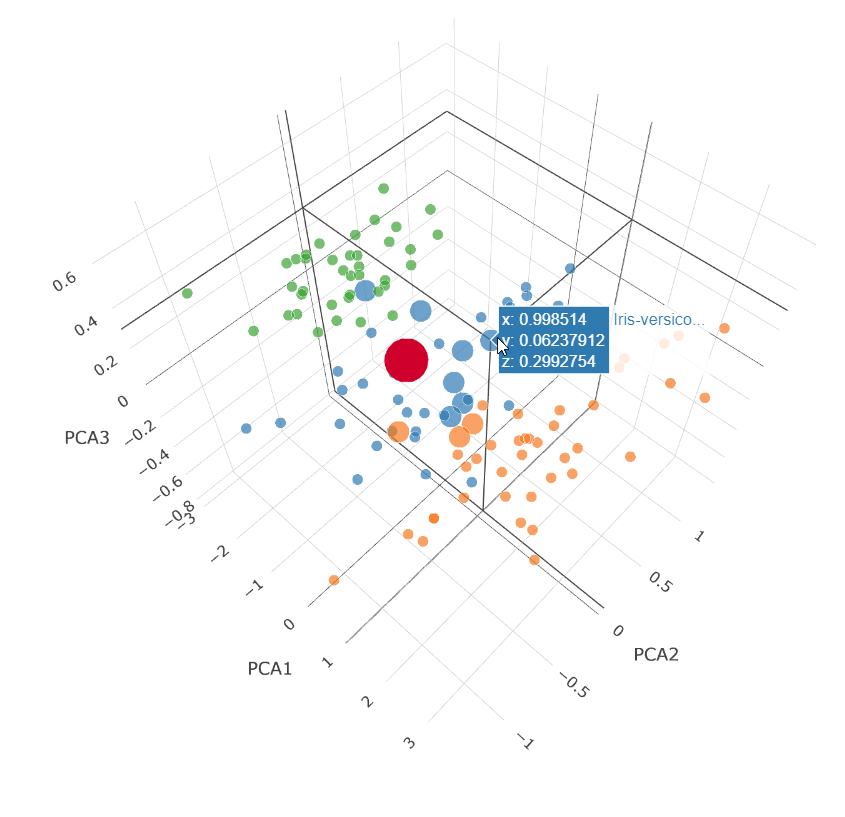
这是一个主成分分析(PCA)图,它将我们的 4 个维度(花瓣宽度和长度、萼片宽度和长度)投射到 3 个维度上。
大的红点是我们的测试查询特征的投影。小点是我们数据集中未选择的点。中等大小的点是我们的 `vector_distance` 查询返回的点。返回了 7 个变色鸢尾点(蓝色)和 3 个弗吉尼亚鸢尾点(橙色)。我们知道该数据点的结果是变色鸢尾。
结论
我们已经快速了解了如何将 Oracle 23ai 的向量数据类型与 Apache Groovy 结合使用。